| ���K�\�� | ���C���h�J�[�h | |
| �s���A�ے� | ^ | ! |
| �ꕶ�� | . | ? |
| 0�ȏ�̕��� | .* | * |
| �P��̐擪 | < | |
| �P��̖��� | > |
| ���� | ���K�\�� | ��� |
| Grep �܂��� grep | [Gg]rep | []�́A�����N���X�ƌ����A�u���P�b�g(�p����)�ň͂����̂����ꂩ�ЂƂƃ}�b�`����}�b�`�����Ɣ��f |
| �p�P�� | [a-zA-Z][a-zA-Z]* | []�i�u���P�b�g�j�̒��Ɂu-�v�i�}�C�i�X�j������A�͈͎w����Ӗ����� []�̒��� - ���w�肵�����ꍇ�Ɍ��� \- �ƑO�ɃG�X�P�[�v���K�v [��-�K] �́A�����Ƀ}�b�` [�@-��] �S�p�J�^�J�i�Ƀ}�b�` [��-��] �S�p�Ђ炪�ȂɃ}�b�` * �́A���O������0��ȏ�̌J��Ԃ� ���F�͈͎w��́A�����R�[�h�̏��������Ƒ傫�����ŋ���Ŏw�肵�܂��B �ȉ��̂悤�Ȕ͈͎w�肪�ł������ł����A�����R�[�h���o���o���Ȃ̂ŁA�ʂɎw�肷��K�v������܂��B [��-��]�̓_���ŁA[�Z��j�O��l�ܘZ������\]�Ƃ��܂��B(���R�A�ǂ�ȏ��ɏ����Ă����܂��܂���B(^^�U [��-��]���_���ŁA[���ΐ��؋��y��]�Ƃ��܂��B |
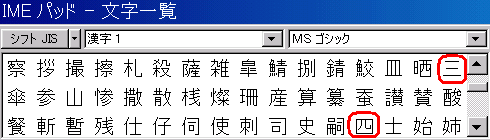 |
||
| �p���s | ^((?![�A-�K]).)*$ | (?!�p�^�[��) �́A�[�������ے�I�Ȑ�ǂݕ\���B |
| �ϐ�������� | [a-zA-Z0-9_-]+ �܂���\w+ | + �́A���O�̃p�^�[����1��ȏ�̌J��Ԃ� \w�́A���p�̉p�������ƃA���_�[�X�R�A�i_�����j�������A�����N���X �G�X�P�[�v �V�[�P���X(����ϐ�) |
| �ϐ�������� | \b[a-zA-Z0-9]+\b | \b�́A�P��̋��E�i�Q�o�C�g�����ɑΉ����Ă��Ȃ��̂Œ��Ӂj + �́A���O�̃p�^�[����1��ȏ�̌J��Ԃ� |
| ���C���A�h���X | [A-Za-z0-9_-]+@[A-Za-z0-9.]+ | |
| 2004/4/17 �̌`���̓��t | [0-9]{4}/[0-9]{1,2} /[0-9]{1,2} | �u���[�X{n}�Œ��O�̃p�^�[����n��J��Ԃ��A {n,}����n��ȏ�A {m,n}�� m��ȏ�An��ȉ��Ƀ}�b�` [0-9]�́A����ϐ� \d�ł��ǂ� |
| �X�֔ԍ� 123-1234 | ([0-9]{3})-([0-9]{4}) | ()�́A�p�^�[���̃O���[�v���B �O���[�v�����������̗D�揇�ʂ������Ȃ�̂ŁA �p�[����(�܂銇��)�̒���]��������ɑS�̂�]�����܂��B �p�[�����̒��̃p�^�[�����o�b�t�@�ɕۑ��ł���̂ŁA�u���ɗp���܂� |
| �s | ^$ �܂���^\n �܂���^\r (�t�@�C���̉��s�w����@�ňقȂ�) | ^ �J���b�g�́A������i�s�j�̍ŏ��ɁA $ �́A������i�s�j�̍Ō�Ƀ}�b�`����B \n�́A�j���[���C�� = LF(\x0a) ���s�i���C���t�B�[�h�j \r�F���^�[�� = CR(\x0d) ���s�i�L�����b�W���^�[���j |
| �X�y�[�X���܂ދs | ^\s*$ | \s�F�X�y�[�X���� = ���p�X�y�[�X(\x20) , �^�u����(�����^�u(\x09),�����^�u(\x0b)) , ���s(CR(\x0d),LF(\x0a)) , ���y�[�W(\x0c) \S�F�X�y�[�X�����ȊO |
| 10�����̍s | ^.{10}$ | . ���s�����ȊO�̔C�ӂ�1���� |
| �w�肵���������ȏ�̍s �����ł́A10�����ȏ�̍s | ^.{10,}$ | . ���s�����ȊO�̔C�ӂ�1���� {n,}����n��ȏ� |
| test �܂��� TEST | test|TEST | | �́A�p�^�[���̘_���a�ŁA�����̃p�^�[���̂����ꂩ |
| ���C���̈����^�C�g�� | ^(To|From|Subject |Date|Cc|Bcc|Fcc| Received|Sender): | ^ ������i�s�j�̍ŏ��Ƀ}�b�`����B |
| This is a desk. This is a book. ��is�̃}�b�` | �Œ��}�b�` .*is �ŒZ�}�b�` .*?is �P��P�ʂ� \b.[^ ]*?is|is | .* �͉��ł��L��������B �ʏ�͍Œ���v�̃��[�����K�p�����B ? �ōŒZ�Ń}�b�`�B \b �P��̋��E�Ƀ}�b�`����B |
| �O��̒P����w�肵������ ��F �u���v�Ɓu�����v | ���.*?���� | .* �͉��ł��L��������B ? �ōŒZ�Ń}�b�` |
| ���C���̈��p���� | ^ *\>.*$ | ^ ������i�s�j�̍ŏ��Ƀ}�b�`����B |
| ���Ă��� �_�u���N�H�[�e�[�V���������� | "("|.[^"]*") �܂��� ".*?" | \�ŃG�X�P�[�v����Ȃ�[�ƁA\�ŃG�X�P�[�v����Ȃ�]�ň͂܂ꂽ�ŏ���^�͔ے� |
| �s���������łȂ��s | ^[^0-9].* | �u���P�b�g(�p����)���̏��߂�^�͔ے� |
| ,��,�̊Ԃ�12���̕��� | ,[^,]{12}, | �r����^�͔ے� |
| google�͏���goo�̂��� | goo[^g] | �r����^�͔ے� |
| �_�u���N�H�[�e�[�V���� ����s���܂� | ".[^"]*$ | $ ������i�s�j�̍Ō�Ƀ}�b�`����B |
| ()�ł�����ꂽ�͈́B 3�d�̓���q���܂ށB �P���� \(.*?\) �ŁA���L�悤�ȕ��������������ƁA���F�̕����Ƀ}�b�`���Ă��܂��̂ŁA���ӁI (���s(���傤��)�ɍs��) �E��HTML�^�O����q�����̐��K�\������щ���́A �T�N���G�f�B�^�f���́u�����v����̋L�q������p�����Ă��������܂��� ���F�e�L�X�g�̊��ʂ̐����A����������q�ɂȂ��Ă��Ȃ��ƁA���[�v���܂��B |
\([^()]* (\([^()]* (\([^()]*[^()]*\)[^()]*)* [^()]*\)[^()]*)* [^()]*\) |
HTML�̃^�O�̓���q�ւ̑Ή����@ ����{�p�^�[�� <[^<>]*> ����őΉ�����^�O(����)�����Ƀ}�b�`���܂��B ����q�ɑΉ����邽�߂̏����Ƃ��� <[^<>]*[^<>]*> �ƕύX���܂��B�i�܂�����q��Ή��B�j �ŁA����L�� [^<>]* �� [^<>]* �̊Ԃ� (<[^<>]*[^<>]*>[^<>]*)* �Ƃ����A�u�i �Ή����銇�ʂ̑g�ݍ��킹�{���ʂƂ͖��W�� 0���ȏ�̕����� �j�� 0��ȏ�J��Ԃ����v �̋L�q��}���B�� <[^<>]*(<[^<>]*[^<>]*>[^<>]*)*[^<>]*> ������łQ�d�̊��ʂɑΉ��B ����Ɂ���L�� [^<>]* �� [^<>]* �̊Ԃ� (<[^<>]*[^<>]*>[^<>]*)* �Ƃ����A�u�i �Ή����銇�ʂ̑g�ݍ��킹�{���ʂƂ͖��W�� 0���ȏ�̕����� �j�� 0��ȏ�J��Ԃ����v�̋L�q��}���B�� <[^<>]*(<[^<>]*(<[^<>]*[^<>]*>[^<>]*)*[^<>]*>[^<>]*)*[^<>]*> ������łR�d�̊��ʂɑΉ��B ���S�d����q�܂őΉ� <[^<>]*(<[^<>]*(<[^<>]*(<[^<>]*[^<>]*>[^<>]*)*[^<>]*>[^<>]*)*[^<>]*>[^<>]*)*[^<>]*> |
| 10182 11128 20080 30020 90180 ��80�ŏI���Ȃ��s | ^.*([^8].|[^0])$ | ^ ������i�s�j�̍ŏ��Ƀ}�b�`����B $ ������i�s�j�̍Ō�Ƀ}�b�`����B |
| html�̃^�O | <(.*?)> | * �́A���O������0��ȏ�̌J��Ԃ� .*�͉��ł��L��������B ? �ōŒZ�Ń}�b�`�B |
| html�̃A���J�[�^�O | <[Aa] [^>]*> | |
| css�̃R�����g /* */ | /\*/?([^/]|[^*]/|\n)*\*/ | |
| �s���ȊO�̓��蕶�� (�����ł́�) (�g�[���X����ɋ����Ă��������܂���) | (?!^)��.* | (?!�p�^�[��) �́A�[�������ے�I�Ȑ�ǂݕ\���B �T�N���G�f�B�^�Ŏg���܂��B |
| �w�肵�������Ŏn�܂�Ȃ��s (�����ł́A�s���� �lj� �ł͂Ȃ��s) | ^(?!�lj�).*$ | |
| �w�肵���������܂܂Ȃ��s (�����ł� �ύX ���܂܂Ȃ��s) | ^(?!.*�ύX).+$ | |
| �w�肵�������ŏI���Ȃ��s (�����ł́A�s���� �ύX �ł͂Ȃ��s) | ^.*(?!�ύX)..$ | ��ǂݔے���g���ꍇ�́A�����ŗL���̕\����u���K�v������܂��B �s����$�ł��܂��s���Ȃ��ꍇ�́A$�̑����\r\n���g���܂��B (���F���L�́A2�����ȉ��̍s�ɂ̓}�b�`���܂���B ���ʂ�perl�݊��̐��K�\���ł́A m/.*(?!�ύX)$/ ����ʓI�ł��B) �@���̍��ڂ̑S�ẮA (�S��) ����ɋ����Ă������������̂ł��B |
| ^.*(?<!�ύX)$ | bregonig.dll �ȂǁA�ے�̖߂�ǂ݂��g����ꍇ�B �s����$�ł��܂��s���Ȃ��ꍇ�́A\r\n���g���܂��B |
|
| ^.*[^��][^�X]$ | �s����$�ł��܂��s���Ȃ��ꍇ�́A\r\n���g���܂��B �@���݂� ����ɋ����Ă��������܂����B |
|
| �w�肵���������܂ލs (�����ł� �ύX ���܂ލs) | .*�ύX.*$ | |
| �n�C�t����������܂ލs | ^[^-]*-[^-]*$ | �u���P�b�g(�p����)���̏��߂�^�͔ے� |
| ���p��2���̂ݘA�� | \S \S | \S�F�X�y�[�X�����ȊO |
| [^ ] [^ ] | �u���P�b�g([�p����])���̏��߂�^�͔ے� | |
| �p���L���̘A��10���ȏ�ŏI���s (�Ⴆ�A���̂悤�ȍs ABCD 123 CUDR-U.MULKO EFGHIJK 25 BLOCK->HANTAI) | ^.* [a-zA-Z0-9<>\.\(\)/-]{10,}$ | []�i�u���P�b�g�j�̒��ŁA�����Ƃ��āu-�v(�n�C�t��)���w�肵�����ꍇ�́A�Ō�Ɏ����Ă��� |
| �S�p���� (���p�����ȊO) | [^ -~�-�] �܂��́A[^\x01-\x7E] | �T�N���G�f�B�^�f���ŁAds14050 ����ɋ����Ă��������܂����B [^ -~�-�]�́AASCII(�`����������������)�Ɣ��p�J�i�ȊO�Ƃ������ƂŁAASCII���䕶��(���s�܂�)��Shift_JIS�̐�s�o�C�g�Ƀ}�b�`���܂��B |
| �S�p���� | [^\x01-\x7E] | �w\x01-\x7E�x�́A�����R�[�h SHIFT_JIS �Ŕ��p�����͈̔� ASCII �ȊO�ŁA���s�Ƀ}�b�`�����ɁA���p�J�i�ɂ̓}�b�`���܂��B |
| ���p���� | [!-~] | ������� ASCII �\���Q�Ɖ����� |
| "�̐����A��s����19����s | ^"(.*?"){18}$ | CSV�� Access �ɃC���|�[�g�����Ƃ��A "�̐�������Ȃ��ăG���[�ɂȂ��� ���}�Q�� �Y���s���A�O�����ĕ������Ă���Ƃ��́A �J�[�\�����߂��̍s�܂Ŏ����Ă����Ă��猟�����Ȃ��ƁA���Ԃ�������܂�(^^�U |
| ���� | ���K�\�� | ��� |
| POSIX �N���X | �Ή�����\�� | �Ӗ� |
|---|---|---|
| [:upper:] | [A-Z] | �啶�� |
| [:lower:] | [a-z] | ������ |
| [:alpha:] | [A-Za-z] | �A���t�@�x�b�g |
| [:alnum:] | [A-Za-z0-9] | �����ƃA���t�@�x�b�g |
| [:digit:] | [0-9] | ���� |
| [:xdigit:] | [0-9A-Fa-f] | 16�i�� |
| [:punct:] | [.,!?:...] | ��Ǔ_ |
| [:blank:] | [ \t] | �X�y�[�X�ƃ^�u |
| [:space:] | [ \t\n\r\f\v] | ���� |
| [:cntrl:] | \c[ | ���䕶�� |
| [:graph:] | [^ \t\n\r\f\v] | ���� |
| [:print:] | [^\t\n\r\f\v] | �����ƃX�y�[�X |
��: [[:upper:]ab] �́A�啶���� a �� b �݂̂Ƀ}�b�`���܂��B
[^[:alnum:]] �́A�u���p�p�����ȊO�̕�����v�Ƀ}�b�`���܂��B
�������̃c�[���Ŏg�p�ł���APOSIX �ɂȂ��N���X�Ƃ��� [:word:] ������܂��B[:word:] �͒ʏ� [:alnum:] �ƃA���_�[�X�R�A�̑g�����ɂȂ�܂��B
����炪�����̃v���O���~���O����Ŏ��ʎq�Ƃ��Ďg�p�ł��镶��������ł�
�@���K�\���Ő��䕶��������������@
http://blog.livedoor.jp/xaicron/archives/50948539.html
�@���p�����ɍ��v���鐳�K�\��
http://www.4d.com/jp/blog/regex-hankaku.html
�@���K�\��(Perl�̏�����)
http://www.komonet.ne.jp/~perl/chap7.htm
| ���L�@ | �����N���X | �Ӗ� |
|---|---|---|
| \w | [a-zA-Z0-9_] | �A���t�@�x�b�g�A�����A���� |
| \W | [^a-zA-Z0-9_] | �A���t�@�x�b�g�A�����A�����ȊO |
| \s | [\r\t\n\f] | �����i�X�y�[�X�A���A�����A�^�u�A���s�����A���C���t�B�[�h�j |
| \S | [^\r\t\n\f] | �����ȊO |
| \d | [0-9] | ���� |
| \D | [^0-9] | �����ȊO |
| ������ | �V�t�gJIS�R�[�h | �A�X�L�[�R�[�h |
|---|---|---|
| �O�P�Q�R�S�T�U�V�W�X | &h824F�`&h8258 | &h30�`&h39 |
| �S�p�A���t�@�x�b�g�啶���i�`�a�b�E�E�j | &h8260�`&h8279 | &h41�`&h5A |
| �S�p�A���t�@�x�b�g�������i�������E�E�j | &h8281�`&h829A | &h61�`&h7A |
| ���� | ���K�\�� | ��� |
| 1�ԖځA2�ԖځA3�Ԗڂ� NO.1�ANO.2�ANO.3�� | (\d+)�Ԗ� /NO.\1 | \d�͐��� + �́A���O�̃p�^�[����1��ȏ�̌J��Ԃ� |
| ���[�}���̖��E�����A���E���� Makoto WATANABE ��WATANABE Makoto | ^([a-zA-Z]+) +([a-zA-Z]+) /\2 \1 | |
| �u10/20'2004�v�� �u2004/10/20�v�� | ([0-9]{1,2})/([0-9]{1,2})'([0-9]{4}) /\3/\1/\2 | [0-9]��\d�ł��ǂ� |
| �u2004/04/17�v�� �u2004�N04��17���v�� | ([0-9]{4})/([0-9]{1,2})/([0-9]{1,2}) /\1�N\2��\3�� | [0-9]��\d�ł��ǂ� |
| �u12.345.12�v�� �u12345.12�v�� ���B�ł́A ������3�����ɁA �u,�v�ł͂Ȃ��u.�v���g���B ������폜�B | (\d{1,3})\.(\d{3})\.(\d\d) /\1\2.\3 | \. �́A���e�����Ƃ��Ắu.�v |
| �u�v�����^�v�� �u�v�����^�[�v�� | �v�����^([^�[]) /�v�����^�[\1 | ^ �́A�u�܂܂�Ă��Ȃ��ꍇ�v�ƌ����ے�I�Ȏw�� �u�[�v�ȊO�̎���1�����܂őI�����Ă����āA�u������e�N�j�b�N |
| �s�����u>�v�łȂ��s�� �u<br>�v��lj� | ([^>])\r\n /\1<br>\r\n | ^ �́A�u�܂܂�Ă��Ȃ��ꍇ�v�ƌ����ے�I�Ȏw�� �O�s�Ɠ����e�N�j�b�N |
| �s�����u,�v�łȂ��s�� �u,�v��lj� | ^(.*[^,])$ /\1, | ^ �́A�u�܂܂�Ă��Ȃ��ꍇ�v�ƌ����ے�I�Ȏw�� ��s�ۂ��Ƃ���ŁA�ϊ�������@ |
| �V���O���N�H�[�e�[�V���� �Ŋ���ꂽ5���ȏ�̐��l���� �V���O���N�H�[�e���V�������O�� | '(\d{5,})'/$1 | �o�b�t�@�Ăяo���́A$1�ł��ł��� |
| �w�肵���������ʼn��s �����ł́A40�����ʼn��s | (.{40})/\1\n | \1 �Ŏw�蕶�����̃o�b�t�@�������o���āA ���s���� \n ��lj� |
| html�̃^�O���� | <!--(.|\n)*-->|<([^>]|\n)*> | |
| �s�̍폜 | ^\n/ step1.�u\r\n/\n�v step2.�u^\n+/�v step3.�u\n/\r\n�v | �e�L�X�g�G�f�B�^�ɕt�����Ă��鐮�`�@�\��A�N���b�v�{�[�h�E�c�[�����g�����ق����֗� |
| �w�肵���������܂ލs���폜 (�����ł� �ύX ���܂ލs) | .*�ύX.*\n/ | ������G�f�B�^�� ���イ�� ����̌f������A���f���p |
| ���{��̍폜 �p���Ζ���{�ꕔ�����폜 | [�A-�K] | |
| �u�s���ȊO�̓��蕶��(�����ł́�)�v����s���܂ł̍폜 (������ƁA��������ɋ����Ă��������܂���) |
(.)��.* /\1\r �܂��́A ^(.[^��]*)��.* /\1\r | ���蕶���̍������A�ʂɃo�b�t�@�ɓ���āA�����߂��e�N�j�b�N�ł��B �u�����\r�͍s���܂ł̎w���\r\n��\r���H�ׂ��Ă��܂��ꍇ�ɓ���܂� |
| ���{�ꕶ����+���p��+�p�� �́u���p�v�ʼn��s |
([��-�K�@-����-��)\]�r]) ([a-zA-Z].*)$ /$1\r\n$2 | �����f�[�^�ŁA1�Z���ɕ����P�ꂪ�����Ă�����̂��A�������āA�P�ꃊ�X�g�ɂ��邽�߂Ɏg���Ă��܂� �����N���X�w��̒��ł� \��O�ɒu���Ȃ��Ă��A���̕������g��\�킵�܂��B |
| ����4���̏ꍇ�́A����0��t�� | ^([0-9]{4})$ /0\1 | |
| ����4���̏ꍇ�́A����0��t�� | ^([0-9]{4})$ /0$& | $& �́A���݂̃X�R�[�v�ōŌ�ɐ����������K�\���̃p�^�[���}�b�`�Ń}�b�`���������� |
| ���� | ���K�\�� | ��� |
 �@�y�V���o�C���́A2022�N05��13���A���z�[���~�̃v�����̏I��������I�ɐ錾���܂����B
�@�y�V���o�C���́A2022�N05��13���A���z�[���~�̃v�����̏I��������I�ɐ錾���܂����B
|
|
![]()