Rust �R�[�h��
Rust �̃v���O��������Љ����̂ł��BChatGPT �AGemini Pro �AClaude �AQwen(���) ) �̃v���O���~���O����̒m�͂͗D�ꂽ���̂ł��BRust �̃R�[�h�������Ƃ��̒��ӁF UTF-8 �ł��BShift-JIS �łȂ����Ƃɒ��Ӊ������B�o�b�N�X���b�V�� �ł��B/ SortTest/ utf_ken_all.csv")?;\ SortTest\ utf_ken_all.csv")?;�ڎ�
�R�[�h��
Hello, World!
�@�v���O����������w�ԍۂɁA Hello, world! �Ƃ����e�L�X�g����ʂɏo�͂��鏬���ȃv���O�������������Ƃ͓`���I�Ȃ��Ƃł��Bhttps://doc.rust-jp.rs/book-ja/ch01-02-hello-world.html rustc helloJP.rs �ŃR���p�C���ł��܂��BhelloJP.rs
// helloJP.rs
//rustc helloJP.rs
use std ::io;
fn main()
{
// ���E��A����ɂ���
println! ("����ɂ���, ���E!");
// �W�����͂�ҋ@
println! ("");
let mut ���� = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
std::fs ���W���[���c�c�t�@�C���̃I�[�v����쐬�A �t�@�C���^�f�B���N�g���̑���println! �F��������R���\�[��(���s���)�ɕ\�����邽�߂̃}�N���ł��B�I ���t���̂��}�N���ł��B���ƈႤ�̂͊��Ăяo��(function call)���������ɁA�\�[�X�R�[�h���ɓW�J����A���͂̃v���O�����ƂƂ��ɃR���p�C�������_�ł��B
Hello_World )������ăR���p�C������K�v������܂��Bcrossterm ���g���ƃe�L�X�g�x�[�X�̃C���^�[�t�F�[�X���쐬�ł��܂��B
[package]
name = "Hello_World"
version = "0.1.0"
edition = "2024"
[dependencies]
crossterm = "0.29.0"
�@main.rs
// Hello, world! �ƕ\�����ꂽ��A�v���O�������I�������ɑҋ@���܂��B
// �L�[������1�����ƁA�����ɂ��̃L�[�̃R�[�h���\������A�v���O�������I�����܂��B
// �d�g��: crossterm::event::read() �́A�ʏ�Enter���K�v�ȃ^�[�~�i���̋�����������A
// �L�[�������ꂽ�u�ԂɃC�x���g���擾���܂��B
//use crossterm::event::{self, Event, KeyCode};
use crossterm::event::{self, Event};
use std ::io::{self, Write};
fn main() -> io::Result<()> {
// Hello World ��\��
println! ("Hello, world!");
println! ("�����L�[����ʼn�ʂ���܂�...");
io::stdout().flush()?;
// �L�[���͂�ҋ@�iEnter�s�v�j
loop {
// �C�x���g�������������`�F�b�N
if event::poll(std::time::Duration::from_millis(100))? {
// �C�x���g��ǂݍ���
if let Event::Key(key_event) = event::read()? {
println! ("Pressed: {:?}", key_event.code);
break; // �����L�[�������ꂽ�烋�[�v����
}
}
}
Ok(())
}
��������(�o�ߎ���)��\��
�@�ȉ��́AGemini Pro �ɋ����Ă���������̂ł��Bstd `�j�������g���āA�o�ߎ��Ԃ��u���ԁE���E�b�v�ɕϊ����A���u0�v�̒P�ʂ��\���ɂ�����@��������܂��BDuration `�i�o�ߎ��ԁj�́A�W���ł͕b����~���b���̍��v���������Ă��܂���BTimeGeminiJP.rs
// TimeGeminiJP.rs
// rustc TimeGeminiJP.rs
// Gemini �ɋ����Ă��炢�܂���
use std ::thread; // �X���b�h�isleep�Ȃǁj���g�����߂̃��W���[��
use std ::time; // ���ԁiDuration, Instant�j���g�����߂̃��W���[��
use std ::io; // ���o�͊֘A�̃g���C�g�A�W�����o�͂Ȃ�
fn main() {
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// �y����m�F�p�z3�b�ԃX���[�v����i�����g�̃R�[�h�ɍ��킹�ĕύX���Ă��������j
let �X���[�v���� = time::Duration ::from_secs(3);
thread::sleep(�X���[�v����);
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration �^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let ���� = ���v�b�� / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let �� = (���v�b�� % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let �b = ���v�b�� % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut �o�� = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if ���� > 0 {
�o��.push_str(&format! ("{}����", ����));
}
// �u���v��0���傫����Ε\���ɒlj�
if �� > 0 {
�o��.push_str(&format! ("{}��", ��));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if �b > 0 {
�o��.push_str(&format! ("{}�b", �b));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if �o��.is_empty() {
�o��.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println! ("�o�ߎ���: {}", �o��);
// �W�����͂�ҋ@
println! ("");
let mut ���� = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
����F
�R�[�h ���� `use std::thread;` �v���O�������ꎞ��~������ `sleep` �@�\���g�����߂ɓǂݍ��݂܂��B `use std::time;` ���Ԃ��v�����邽�߂̋@�\�i`Instant` �� `Duration `�j��ǂݍ��݂܂��B `fn main() {` �v���O�����̃��C�����i�������珈�����n�܂�܂��j�B `let �J�n���� = time::Instant::now();` ���݂̎������擾���A�X�g�b�v�E�H�b�`�̃X�^�[�g�n�_�Ƃ��� `�J�n����` �ɕۑ����܂��B `let �X���[�v���� = ...` �ҋ@�����鎞�Ԃ�ݒ肵�܂��i�����ł̓e�X�g�p��3�b���쐬�j�B `thread::sleep(�X���[�v����);` �w�肵�����Ԃ����v���O�����̏������~�i�X���[�v�j�����܂��B `let �o�ߎ��� = �J�n����.elapsed();` �X�^�[�g�n�_�i`�J�n����`�j���猻�݂܂ł̌o�ߎ��Ԃ��v�Z���� `�o�ߎ���` �ɓ���܂��B `let ���v�b�� = �o�ߎ���.as_secs();` �o�ߎ��Ԃ��u�b�P�ʁv�̐����i�[���͐�̂āj�Ƃ��Ď��o���܂��B `let ���� = ���v�b�� / 3600;` 1���Ԃ�3600�b�Ȃ̂ŁA���v�b����3600�Ŋ����āu���ԁv�����߂܂��B `let �� = (���v�b�� % 3600) / 60;` 1���Ԃɖ����Ȃ��c��b���i`% 3600`�j��60�Ŋ����āu���v�����߂܂��B���Z�q�ƋL��
�Ō�Ɋ���ꂸ�Ɏc�����b�����A���̂܂܁u�b�v�ɂȂ�܂��B `let mut �o�� = String::new();` ���ʂ̕��������邽�߂̋�̔��i������j�����܂��B��ŏ��������̂� `mut`�i�ύX�\�j�ɂ��܂��Bmut (mutable �ύX�\)�v��t���邱�ƂŁA���̕ϐ��͒l��ύX���Ă��\��Ȃ��A `if ���� > 0 { ... }` �����u���ԁv��0�łȂ���A������Ɂu�����ԁv��lj����܂��B�i0�Ȃ牽�����܂���j �o��.push_str(& format!("{}����", ����)) �ϐ��������ɎQ�Ɠn������Ƃ��͕ϐ��̑O�Ɂu& �v��t���܂��B�n�����͎̂Q�Ƃŏ��L���͌��Ɏc��܂��BRust�̎Q�Ɓi&�j�𗝉����� format!�}�N�� `if �� > 0 { ... }` �����u���v��0�łȂ���A������Ɂu�����v��lj����܂��B `if �b > 0 { ... }` �����u�b�v��0�łȂ���A������Ɂu���b�v��lj����܂��B `if �o��.is_empty() { ... }` �����v�Z���ʂ��S��0�i1�b�����Ȃǁj�ʼn����������Ȃ��ꍇ�A�u0�b�v�Ɠ���܂��B `println! ("�o�ߎ���: {}", �o��);` ������������������s��ʁi�^�[�~�i���j�ɕ\�����܂��B
�����^�̍ŏ��l�A�ő�l��\��
// Gemini pro �ɋ����Ă��炢�܂���
// �����^�̍ŏ��l�A�ő�l��\�����܂�
// MinMax2JP.rs
// rustc MinMax2JP.rs
use std::io;
use std::fmt::Display;
/// ������3�����Ƃ̃J���}��蕶����ɕϊ�����W�F�l���b�N��
fn �J���}��蕶�����<T>(n: T) -> String
where
T: Display + PartialOrd + From<u8> + Copy
{
let s = n.to_string();
let mut ���� = String::new();
// ���̐����ǂ�����i0��菬�������j
let ���̐��� = n < T::from(0);
// ���������݂̂����o���i�}�C�i�X�L���������j
let �������� = if ���̐��� { &s[1..] } else { &s };
for (i, c) in ��������.chars().rev().enumerate() {
if i > 0 && i % 3 == 0 {
����.push(',');
}
����.push(c);
}
if ���̐��� {
����.push('-');
}
����.chars().rev().collect()
}
fn main() {
// i128 �� u128 ����������OK�I
println!("i128 min: {}", �J���}��蕶�����(i128::MIN));
println!("i128 max: {}", �J���}��蕶�����(i128::MAX));
println!("u128 max: {}", �J���}��蕶�����(u128::MAX));
// ���łɑ��̌^�ł������܂�
println!("i32 min: {}", �J���}��蕶�����(-1234567i32));
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
�@���̃R�[�h�������Ă��������̎��� Gemini �Ƃ̂����ł��B���F Rust�R�[�h���g�����ő�ŏ��̎擾���@�������Ă��������A�L��������܂��BGemini�F
�����������t�����������A��ϊ������v���܂��I
�����R�[�h UTF-16 �Ńt�@�C���ۑ�
�@�ȉ��̃R�[�h�� Gemini Pro �ɋ����Ă���������̂ł��Bencode_utf16 ()` �����Ŏ����ł��܂��B
// Gemini pro �ɋ����Ă��炢�܂���
//rustc SaveUTF16.rs
use std::fs::File;
use std::io::{BufWriter, Write};
use std::io;
fn main() -> std::io::Result<()> { // <- Result��Ԃ��Ɛ錾���Ă��܂�
let content = "����ɂ��́A���E�I\n�W�����C�u���������� UTF-16 �ŕۑ��I";
let file_path = "output_std_utf16.txt";
let file = File::create(file_path)?;
let mut writer = BufWriter::new(file);
// 1. BOM ���������� (Little Endian �̏ꍇ�� FF FE)
writer.write_all(&[0xFF, 0xFE])?;
// 2. ������� UTF-16 �̃C�e���[�^�ɕϊ����Au16 �� u8 (LE) �ɕ������ď�������
for u16_char in content.encode_utf16 () {
// u16 �� ���g���G���f�B�A���̃o�C�g�� [u8; 2] �ɕϊ�
let bytes = u16_char.to_le_bytes();
writer.write_all(&bytes)?;
}
writer.flush()?;
println!("�ۑ�����: {}", file_path);
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
Ok(()) //����I���i`Ok`�j��Ԃ���悤�ɂ���
}
Ok(()) �F `Result` �^�́u�����v��\���l�ł��B���g�� `()` �́u��̒l�i���ɕԂ��f�[�^�͂Ȃ��j�v���Ӗ����܂��B���F �R���p�C�����ďo���� exe �t�@�C�������s���Ă��A���s��ʂ��u���ɕ��Ă��܂��āA�G���[�E���b�Z�[�W�Ȃnj����܂���B�G���[���b�Z�[�W���m�F���� �ɂ́A�v���W�F�N�g�̃t�H���_���� PowerShell ���J���� cargo run �����s���܂��B�^�[�~�i���ŊJ�� �v���w�肵�܂��B�E�̉�ʂ��Q�Ɖ������BPowerShell �E�B���h�E�������ŊJ�� �v��I��)cargo run �̃R�}���h����͂��܂��Bfn main() �̏������F
�@����2�̈Ⴂ��**�u�G���[�i���s�j�����������Ƃ��ɁA������ǂ��������v**�Ƃ����_�ɂ���܂��B
�@��{�́A**�u`?` ���Z�q���g���Ċy�ɃG���[�������������Ȃ�A�߂�l����������g���v**�Ƃ������Ƃł��B
�@### 1. `
fn main() { ` �i��{�̌`�j
�@����͍ł��W���I�ȏ������ł��B
Rust�� `main` ���́A�f�t�H���g�ł́u�����Ԃ��Ȃ��i���m�ɂ� `()` ���j�b�g�^��Ԃ��j�v���ƂɂȂ��Ă��܂��B
* **����:** ��ԃV���v���ł��B
* **�G���[����:** �����ŃG���[�����������ꍇ�A�����Ŋ��S�ɏ��������邩�A�v���O�����������I���i�p�j�b�N�j������K�v������܂��B
* **`?` ���Z�q:** **�g���܂���B**
**��:**
use std::fs::File;
fn main() {
// �t�@�C�����J���Ƃ��A���s������ unwrap() �Ńp�j�b�N�i�����I���j�����邵���Ȃ�
let f = File::open("hello.txt").unwrap();
}
�@### 2. `
fn main() -> io::Result<()> { ` �i�G���[��Ԃ��`�j
�@������́A�u`main` �����̂��G���[��Ԃ��\��������v�Ɛ錾���鏑�����ł��B
`io::Result<()>` �́A�u���������牽�����Ȃ� `()`�A���s������ `io::Error` ��Ԃ��v�Ƃ����Ӗ��ł��B
* **����:** �G���[�������� `main` ������G���[���u�O�iOS/�����^�C���j�v�ɓ����邱�Ƃ��ł��܂��B
* **�G���[����:** �G���[���������ăv���O�������I�������ہARust�������I�ɃG���[���e���R���\�[���Ɍ��₷���\�����A�I���R�[�h�iExit Code�j���[���ɂ��Ă���܂��B
* **`?` ���Z�q:** **�g���܂��B** ���ꂪ�ő�̃����b�g�ł��B
**��:**
use std::fs::File;
use std::io;
fn main() -> io::Result<()> {
// �t�@�C�����J���B���s������u?�v�������ɃG���[��Ԃ��ďI�����Ă����
let f = File::open("hello.txt")?;
Ok(()) // �Ō�Ɂu�����v��\�� Ok(()) ��Ԃ��K�v������
}
### ��̓I�ȓ���̈Ⴂ�i��r�j
�u���݂��Ȃ��t�@�C�����J�����Ƃ����ꍇ�v�̎��s���ʂ̈Ⴂ�̗�F
���� `fn main() { ... .unwrap() }` `fn main() -> io::Result<()> { ... ? }` **������** �G���[�������ʓ|�i`unwrap` �� `match ` ���K�v�j **`?` ��t���邾���ŃX�b�L��������** **���s����** �v���O�������p�j�b�N�iPanic�j���� �G���[���e��\�����ĐÂ��ɏI������ **�G���[�\����** `thread 'main' panicked at ...` `Error: Os { code: 2, kind: NotFound, ... }`
### �ǂ��g�������邩
�ȉ��̊�Ŏg��������̂������ł��B
1. **`
fn main() { ` ���g���Ƃ�**
* `println!("Hello, world!");` �����̂悤�ȊȒP�ȃv���O�����B
* �v�Z�����ȂǁA�G���[�i�t�@�C���̓ǂݏ�����ʐM�j���������Ȃ��v���O�����B
2. **`
fn main() -> io::Result<()> { ` ���g���Ƃ�**
* **�t�@�C���̓ǂݏ���**���s���Ƃ��B
* **���[�U�[����̓���**���t����Ƃ��B
* �u���s���邩������Ȃ������v���܂܂�Ă���A`?` ���Z�q���g���ăR�[�h�����ꂢ�ɏ��������Ƃ��B
�@�t�@�C���̑����O���Ƃ̂����i���͂Ȃǁj���o�Ă�����A**��҂� `-> io::Result<()>` �̌`�ɐ�ւ���**�̂���ʓI�ł��B
�@�������邱�ƂŁA`?` ���Z�q���g����悤�ɂȂ�ARust���L�́u���S���Ȍ��ȃG���[�����v��̌��ł���悤�ɂȂ�܂��B
�@�Ӑ}�I�ɑ��݂��Ȃ��t�@�C�������w�肵�Ď��s���A�G���[���b�Z�[�W���ǂ��ς�邩���m�F����ƁA�Ⴂ�������ł��܂��H
// not_found.rs
// rustc not_found.rs
use std::fs::File;
use std::io;
// �߂�l������p�^�[��
fn main() -> io::Result<()> {
// ���݂��Ȃ��t�@�C�����w�肵�Ă݂Ă�������
let _f = File::open("not_found.txt")?;
Ok(()) // �Ō�Ɂu�����v��\�� Ok(()) ��Ԃ��K�v������
}
encode_utf16 �Fhttps://mojoauth.com/character-encoding-decoding/utf-16-encoding--rust https://doc.rust-lang.org/std/str/struct.EncodeUtf16.html https://leaysgur.github.io/posts/2024/06/25/085850/
// Gemini pro �ɋ����Ă��炢�܂���
// SaveUTF16ExternCrate
use std::fs::File;
use std::io::Write;
use encoding_rs::UTF_16LE;
use std::io;
fn main() -> std::io::Result<()> {
let content = "����ɂ��́A���E�I\n`encoding_rs` ���g���� UTF-16 �ŕۑ��I";
let file_path = "output_utf16le.txt";
// 1. UTF-16LE �ɃG���R�[�h
// .encode() �� (Cow<[u8]>, encoding, bool) ��Ԃ��܂�
let (encoded_bytes, _, _) = UTF_16LE.encode(content);
// 2. �t�@�C�����쐬
let mut file = File::create(file_path)?;
// 3. BOM (Byte Order Mark) ���������� (0xFF, 0xFE)
// encoding_rs �̓f�t�H���g�ł� BOM ��t���Ȃ����߁A�蓮�Œlj����܂�
file.write_all(&[0xFF, 0xFE])?;
// 4. �G���R�[�h���ꂽ�{������������
file.write_all(&encoded_bytes)?;
println!("�ۑ�����: {}", file_path);
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
Ok(())
}
Gemini ���o���̔F�������킹�邽�߂ɒ�Ă��Ă����v���O�����ł��BUNICODE �ɂ́AUTF-16 �ȊO�� UTF-8 ������܂��B
// Gemini pro �ɋ����Ă��炢�܂���
// SaveUTF16ExternCrate
use std::fs::File;
use std::io::{Read, Write};
use encoding_rs::UTF_16LE;
use std::io;
fn main() -> std::io::Result<()> {
let content = "��"; // ���{�� 1����
let file_path = "debug_test.txt";
// 1. �G���R�[�h
let (encoded_bytes, _, _) = UTF_16LE.encode(content);
// 2. ��������
let mut file = File::create(file_path)?;
file.write_all(&[0xFF, 0xFE])?; // BOM
file.write_all(&encoded_bytes)?;
drop(file); // �t�@�C�����m���ɕ���
// 3. �y���z�ۑ����ꂽ�t�@�C�����u�o�C�g��v�Ƃ��ēǂݒ���
let mut reader = File::open(file_path)?;
let mut buffer = Vec ::new();
reader.read_to_end(&mut buffer)?;
println!("�ۑ����ꂽ�o�C�g��: {:X?}", buffer);
// ����
if buffer.starts_with(&[0xFF, 0xFE]) {
println!("����: ����́yUTF-16 LE (BOM����)�z�ł��I");
} else if buffer.contains(&0x00) {
println!("����: 0x00 ���܂܂�Ă���̂� UTF-16 �̉\���������ł��B");
} else {
println!("����: BOM���Ȃ��A0x00���Ȃ���� UTF-8 �Ɣ��肳��Ă���\��������܂��B");
}
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
Ok(())
}
�x�N�^�[�^ (Vec<T>) �́A����̌^ (T) �̗v�f��ێ������ϒ��z�� �ł��B�x�N�^�̏������ɂ�`vec!`�}�N�����g�p �ł��܂��Bhttps://doc.rust-lang.org/rust-by-example/ja/std/vec.html https://rust-tech.nkhn37.net/rust-vec-basic/ https://maku77.github.io/p/jku3biq/ https://doc.rust-jp.rs/book-ja/ch08-01-vectors.html
// Gemini pro �ɋ����Ă��炢�܂���
use std::fs;
use std::io;
fn main() -> std::io::Result<()> {
// 1. �o�C�g��Ƃ��ēǂݍ���
let bytes = fs::read("output_std_utf16.txt")?;
// 2. �擪2�o�C�g(BOM)���X�L�b�v���A2�o�C�g���ƂɌ������� u16 �̔z��ɂ���
// (BOM���Ȃ��t�@�C���̏ꍇ�� bytes[2..] �ł͂Ȃ� bytes.as_slice() ���g���܂�)
let u16_vec: Vec <u16> = bytes[2..]
.chunks_exact(2)
.map(|chunk| u16::from_le_bytes([chunk[0], chunk[1]]))
.collect();
// 3. String (UTF-8) �ɕϊ�
let content = String::from_utf16(&u16_vec).unwrap();
println!("{}", content);
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
Ok(())
}
�e�L�X�g(ShiftJIS)�� UTF-8 ��
�@Shift JIS �e�L�X�g�t�@�C����ǂݍ���ŁA�����R�[�h�� UTF8(BOM �t��) �ɕϊ����ăe�L�X�g�t�@�C���o�͂��܂��BShiftJIS_2_UTF8JP
[package]
name = "ShiftJIS_2_UTF8JP"
version = "0.1.0"
edition = "2024"
[dependencies]
encoding_rs = "0.8.35"
rfd = "0.17.2"
�@main.rs
//ChatGPT �ɂ��
use encoding_rs ::SHIFT_JIS;
use std::fs ;
use std ::io::Write;
use std ::path::Path;
use std ::io;
// �t�@�C���I���_�C�A���O��\��
let �t�@�C���� = rfd ::FileDialog ::new()
.add_filter("Text", &["txt"])
.pick_file();
if let Some (path) = �t�@�C���� {
println! ("�I�����ꂽ�t�@�C��: {:?}", path);
// �o�C�i���œǂݍ���
let bytes = fs:: read(&path).expect("�t�@�C���ǂݍ��ݎ��s");
// Shift JIS �� UTF-8 �Ƀf�R�[�h
let (cow, _, had_errors) = SHIFT_JIS.decode(&bytes);
if had_errors {
println! ("�x��: �f�R�[�h�G���[������܂���");
}
let utf8_text = cow.to_string();
// �V�����t�@�C�������쐬
let original_stem = path.file_stem().unwrap().to_string_lossy();
let �V�t�@�C���� = format! ("{}UTF8BOM.txt", original_stem);
let parent = path.parent().unwrap_or(Path::new("."));
let �V�p�X = parent.join(�V�t�@�C����);
// UTF-8 �ŕۑ�
let mut file = fs:: File::create(&�V�p�X).expect("�t�@�C���쐬���s");
// UTF-8 BOM ���ɏ�������
file.write_all(&[0xEF, 0xBB, 0xBF]).expect("BOM�������ݎ��s");
// �{������������
file.write_all(utf8_text.as_bytes()).expect("�t�@�C���������ݎ��s");
println! ("UTF-8 �ɕϊ����ĕۑ����܂���: {:?}", �V�p�X);
} else {
println! ("�t�@�C�����I������܂���ł���");
}
// �W�����͂�ҋ@
println! ("");
let mut ���� = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
https://doc.rust-lang.org/rust-by-example/ja/std_misc/fs.html fs::remove_file �́A�t�@�C���V�X�e������t�@�C�����폜���܂��Bhttps://doc.rust-lang.org/std/fs/fn.remove_file.html Some(path)
enum Option<T> {
Some(T),
None,
}
Some(path) �� �u���g������ꍇ�v�^�v���ytuple�z �Ƃ́A�����t����ꂽ�����̗v�f�ō\�������u�g�v�̂��Ƃł��B
// ��: Some(T)�̎g�p
let some_number = Some(5);
let some_string = Some("hello");
https://zenn.dev/mebiusbox/books/22d4c1ed9b0003/viewer/0e7a37 https://rusty.pages.dev/tuple/
�@rfd �� `pick_file()` �̖߂�l
let file = rfd::FileDialog::new().pick_file();
`pick_file()` �̖߂�l�́F
Option<PathBuf >
�ɂȂ�܂��B�܂�F
�� �߂�l �t�@�C����I�� `Some(PathBuf )` �L�����Z������ `None`
Rust �ł́u�l�����邩������Ȃ��v���̂� Option �ŕ\���܂��B
Rust �́A�u�l�������\���v��K���l�������錾��Ȃ̂ŁARust �� null ���֎~���Ă�������`Option` ���g���܂��B
Option<T>
���g�� 2��ނ����ł��F
Some(�l) // �l����
None // �l�Ȃ�
if let Some(path) = file �́A�p�^�[���}�b�`�ŁA���� **1�s�ŏ������֗��\��**�ł��B
1. file �� Some ���`�F�b�N
2. ���g�����o��
3. None �Ȃ疳��
�ufile �̒��g�����݂���Ȃ�A����� path �Ɏ��o���v�Ƃ����Ӗ��ł��B
���ۂ́A���o���Ȃ���`�F�b�N���Ă��邾���Ȃ�ł��B
�W�J����Ɖ��̈Ӗ��ɂȂ�܂��F
match file {
Some(path) => {
// file �� Some �Ȃ�
println!("�I�����ꂽ�t�@�C��: {:?}", path);
// ���g�����o���� path �Ƃ����ϐ��ɓ����
}
None => {
// None �Ȃ牽�����Ȃ�
}
}
�}������ƁF
file
���� Some("C:\test.txt") �� path = "C:\test.txt"
���� None �� ���s����Ȃ�
�@������[�߂邽�߂̗�F
let x = Some(10);
if let Some(value) = x {
println!("{}", value);
}
�� 10 ���\�������
let x: Option<i32> = None;
if let Some(value) = x {
println!("{}", value);
}
�� �����N���Ȃ�
match�A�[���L�@ https://zenn.dev/mebiusbox/books/22d4c1ed9b0003/viewer/5adf8a https://doc.rust-jp.rs/book-ja/ch18-03-pattern-syntax.html https://note.com/leapcell/n/n1c43c869f9ee https://ytyaru.hatenablog.com/entry/2020/10/22/000000 �e�L�X�g�E�t�@�C�����s�\�[�g
�@�P�D�t�@�C�����J���_�C�A���O�ŁA�e�L�X�g�E�t�@�C����I�т܂��B
�e�L�X�g�E�t�@�C���̕����R�[�h�́AShift JIS �CUTF-8�AUTF16 �̂�����ł������܂��B�����R�[�h UTF-16 �Ńt�@�C���ۑ� ���Q�Ɖ������BChatGPT �ɋ����Ă�������R�[�h�ł��BGemini �ɋ����Ă�������R�[�h �AClaude�i�N���[�h�j�ɋ����Ă�������R�[�h ���Q�Ɖ������BLineSort
[package]
name = "LineSort"
version = "0.1.0"
edition = "2024"
[dependencies]
encoding_rs = "0.8.35"
rfd = "0.17.2"
�@main.rs
// ChatGPT �ɂ��
// ���ԕ\���� Gemini �ɂ��
// use encoding_rs::{SHIFT_JIS, UTF_8, UTF_16LE, UTF_16BE, Encoding};
use encoding_rs ::{SHIFT_JIS, UTF_8, UTF_16LE, UTF_16BE};
use std::fs ;
use std ::io::Write;
use std ::path::Path;
use std ::{time, io}; //���ԁiDuration , Instant�j�ƕW�����o��
#[derive(Clone, Copy)]
#[derive(Debug)]
enum TextEncoding {
Utf8,
Utf8Bom,
Utf16Le,
Utf16Be,
ShiftJis,
}
/// �����R�[�h����{UTF-8 �ɕϊ�
fn decode_text (bytes: &[u8]) -> (String, TextEncoding) {
// UTF-8 BOM
if bytes.starts_with(&[0xEF, 0xBB, 0xBF]) {
let (cow, _, _) = UTF_8.decode(&bytes[3..]); //0xEF 0xBB 0xBF ��3�o�C�g
return (cow.to_string(), TextEncoding::Utf8Bom);
}
// UTF-16 LE BOM
if bytes.starts_with(&[0xFF, 0xFE]) {
let (cow, _, _) = UTF_16LE.decode(&bytes[2..]);
return (cow.to_string(), TextEncoding::Utf16Le); //Windows UNICODE
}
// UTF-16 BE BOM
if bytes.starts_with(&[0xFE, 0xFF]) {
let (cow, _, _) = UTF_16BE.decode(&bytes[2..]);
return (cow.to_string(), TextEncoding::Utf16Be);
}
// �� BOM ���� UTF-8 ������
let (cow, _, had_errors ) = UTF_8.decode(bytes);
if !had_errors {
return (cow.to_string(), TextEncoding::Utf8); //BOM�����FUTF8��������
//�G���[�łȂ���� UTF8
}
// �Ō�� Shift JIS
let (cow, _, _) = SHIFT_JIS.decode(bytes);
(cow.to_string(), TextEncoding::ShiftJis)
}
/// UTF-8 String �����̕����R�[�h�֕ϊ�
fn encode_text (text: &str, enc: TextEncoding) -> Vec <u8> {
match enc {
TextEncoding::Utf8 => text.as_bytes().to_vec(),
TextEncoding::Utf8Bom => {
let mut v = vec![0xEF, 0xBB, 0xBF];
v.extend_from_slice(text.as_bytes());
v
}
TextEncoding::Utf16Le => {
let (cow, _, _) = UTF_16LE.encode(text);
let mut v = vec![];
v.extend_from_slice(&cow);
v
}
TextEncoding::Utf16Be => {
let (cow, _, _) = UTF_16BE.encode(text);
let mut v = vec![];
v.extend_from_slice(&cow);
v
}
TextEncoding::ShiftJis => {
let (cow, _, _) = SHIFT_JIS.encode(text);
cow.to_vec()
}
}
}
/// �����N�C�b�N�\�[�g�iin-place�j
// fn quick_sort(lines: &mut [String]) {
// if lines.len() <= 1 {
// return;
// }
//
// let pivot = lines.len() / 2;
// let pivot_value = lines[pivot].clone();
//
// let mut left = 0;
// let mut right = lines.len() - 1;
//
// while left <= right {
// while lines[left] < pivot_value {
// left += 1;
// }
// while lines[right] > pivot_value {
// if right == 0 { break; }
// right -= 1;
// }
// if left <= right {
// lines.swap(left, right);
// left += 1;
// if right == 0 { break; }
// right -= 1;
// }
// }
//
// let (l, r) = lines.split_at_mut(left);
// quick_sort(l);
// quick_sort(r);
// }
// �@ �t�@�C���I��
let path = match rfd ::FileDialog ::new().pick_file() {
Some (p) => p,
None => return,
};
// ���̎����i�v���J�n�n�_�j���擾
let now = time::Instant::now();
// �A �ǂݍ���
let bytes = fs:: read(&path).expect("�ǂݍ��ݎ��s");
let (text, encoding) = decode_text (&bytes);
// CRLF / LF ���Ή�
let mut lines: Vec <String> = text
.lines()
.map(|s| s.to_string())
.collect();
println! ("�s��: {}", lines.len());
// // �B �N�C�b�N�\�[�g
//quick_sort(&mut lines);
// �B �\�[�g�i���S�E�����E�X�^�b�N�I�[�o�[�t���[���Ȃ��j
lines.sort_unstable ();
// ���s�R�[�h��ݒ�
let use_crlf = matches!(
encoding,
TextEncoding::ShiftJis | TextEncoding::Utf16Le | TextEncoding::Utf16Be
);
let sorted_text = if use_crlf {
lines.join("\r\n")
} else {
lines.join("\n")
};
// �o�̓t�@�C����
let stem = path.file_stem().unwrap().to_string_lossy();
let parent = path.parent().unwrap_or(Path::new("."));
let out_path = parent.join(format! ("{}SortedChatGPT.txt", stem));
// ���̕����R�[�h�ŕۑ�
let encoded = encode_text (&sorted_text, encoding);
let mut file = fs:: File::create(&out_path).expect("�쐬���s");
file.write_all(&encoded).expect("�������ݎ��s");
println! ("�\�[�g����: {:?}", out_path);
// �ŏ��̎�������̌o�ߎ��Ԃ�\��
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration �^�j
let elapsed = now.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let total_secs = elapsed.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let hours = total_secs / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let minutes = (total_secs % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let seconds = total_secs % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut output = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if hours > 0 {
output.push_str(&format! ("{}����", hours));
}
// �u���v��0���傫����Ε\���ɒlj�
if minutes > 0 {
output.push_str(&format! ("{}��", minutes));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if seconds > 0 {
output.push_str(&format! ("{}�b", seconds));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if output.is_empty() {
output.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println! ("�o�ߎ���: {}", output);
println!("���肳�ꂽ�����R�[�h: {:?}", encoding);
// �W�����͂�ҋ@
println! ("");
let mut input = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut input).unwrap();
}
had_errors �F�G���[��https://docs.rs/encoding_rs/latest/encoding_rs/ https://ittrip.xyz/rust/rust-file-encoding-conversion #[derive] �F�R�[�h�����Ă���鑮���Bhttps://www.ne.jp/asahi/hishidama/home/tech/rust/attribute/derive.html Debug �FDebug�g���C�g�̎�������������Aprintln!("{:?}")�Œl���o�͂ł���悤�ɂȂ�B�e�L�X�g�E�t�@�C�����s�\�[�g Gemini
�@ChatGPT �Ɠ������Ƃ� Gemini �ɕ����܂����B���x������肵�āA���L�̃R�[�h���܂����BVec <u8>`) �ɕϊ�������ԂŃN�C�b�N�\�[�g��������**�K�v������܂��Bsort_unstable `�j�v**���g�p���ABOM����s�R�[�h�������ɃN���[�j���O���Ă��珈������A�ł����S�ȃR�[�h���쐬���܂����Bdetect_and_decode `)**:sort_unstable `)**:sort_by �̍����Q�Ɖ������BLineSortGemini
[package]
name = "LineSortGemini"
version = "0.1.0"
edition = "2021"
[dependencies]
rfd = "0.17.2" # �t�@�C���_�C�A���O
encoding_rs = "0.8" # �����R�[�h�ϊ�
charset-normalizer-rs = "1.1.0" # �����R�[�h�������� �����Ԃ� _ �łȂ��� - �ł��邱�Ƃɒ���
chardetng = "0.1" # �����x�ȕ����R�[�h����
�@main.rs
use chardetng ::EncodingDetector;
//use encoding_rs::{Encoding, UTF_8};
use encoding_rs ::{Encoding};
use rfd ::FileDialog;
use std ::fs::{self, File};
use std ::io::Read;
use std ::path::{Path, PathBuf };
use std ::{time, io}; //���ԁiDuration , Instant�j�ƕW�����o��
// 1. �t�@�C�����J���_�C�A���O
let file_path = FileDialog ::new()
.add_filter("Text Files", &["txt", "csv", "log"])
.pick_file()
.ok_or("�t�@�C�����I������܂���ł����B")?;
// ���̎����i�v���J�n�n�_�j���擾
let now = time::Instant::now();
println! ("�ǂݍ��ݒ�: {:?}", file_path.file_name().unwrap());
// 2. �t�@�C�����o�C�i���Ƃ��ēǂݍ���
let mut file = File::open(&file_path)?;
let mut buffer = Vec ::new();
file.read_to_end(&mut buffer)?;
// 3. �����R�[�h����ƃf�R�[�h (BOM�Ή�)
let (encoding, decoded_string) = detect_and_decode (&buffer);
println! ("���肳�ꂽ�����R�[�h: {}", encoding.name());
// 4. �s�ɕ��� (CRLF / LF ���݂ɑΉ�)
// .lines() �͉��s����(\r��\n)�������I�Ɏ�菜���Ă���܂�
let mut lines: Vec <&str> = decoded_string.lines().collect();
let original_count = lines.len();
println! ("�s��: {} �s", original_count);
// 5. �s�\�[�g (Rust�W���� sort_unstable ���g�p)
// Unicode�R�[�h�|�C���g��: �L�� < ���� < �p�� < �Ђ炪�� < �J�^�J�i < ����
println! ("�\�[�g��...");
lines.sort_unstable ();
// 6. �o�̓f�[�^�̍쐬
// Windows�̕W���ɍ��킹�� CRLF (\r\n) �Ō������܂�
let output_text = lines.join("\r\n");
// 7. ���̕����R�[�h�ɃG���R�[�h���ĕۑ�
// �t�@�C������
let output_path = create_output_path (&file_path);
// �G���R�[�h
// (BOM�t���������ꍇ�́Aencoding_rs �͒ʏ�BOM�Ȃ��ŏo�͂��邽�߁A�K�v�Ȃ�t�^�\�����A����͕W���I�ȋ����Ƃ���)
let (encoded_bytes, _, _) = encoding.encode(&output_text);
// ��������
fs::write(&output_path, &encoded_bytes)?;
println! ("�������܂����I");
println! ("�o�̓t�@�C��: {:?}", output_path.file_name().unwrap());
// �ŏ��̎�������̌o�ߎ��Ԃ�\��
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration �^�j
let elapsed = now.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let total_secs = elapsed.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let hours = total_secs / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let minutes = (total_secs % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let seconds = total_secs % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut output = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if hours > 0 {
output.push_str(&format! ("{}����", hours));
}
// �u���v��0���傫����Ε\���ɒlj�
if minutes > 0 {
output.push_str(&format! ("{}��", minutes));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if seconds > 0 {
output.push_str(&format! ("{}�b", seconds));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if output.is_empty() {
output.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println! ("�o�ߎ���: {}", output);
// �W�����͂�ҋ@
println! ("");
let mut input = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut input).unwrap();
Ok(())
}
/// �����R�[�h�肵�ăf�R�[�h�����
/// BOM����������D�悵�A�Ȃ���� chardetng �Ő�������
fn detect_and_decode (buffer: &[u8]) -> (&'static Encoding, String) {
// 1. �܂�BOM�i�o�C�g���}�[�N�j���m�F����
// encoding_rs �� for_bom �� BOM ��������̃G���R�[�f�B���O��Ԃ�
if let Some ((enc, bom_len)) = Encoding::for_bom(buffer) {
// BOM���������ꍇ�A���̕������������ăf�R�[�h
let (decoded, _, _) = enc.decode(&buffer[bom_len..]);
return (enc, decoded.into_owned());
}
// 2. BOM���Ȃ��ꍇ�Achardetng �Œ��g����͂��Đ�������
let mut detector = EncodingDetector::new();
detector.feed(buffer, true);
let encoding = detector.guess(None, true); // TLD�w��Ȃ��A���{�ꓙ�̉\�����܂߂�
// 3. ���肵���G���R�[�f�B���O�Ńf�R�[�h
// decode_with_bom_removal �͔O�̂��ߓ���Ă��邪�A��L�ŏ����ς݂Ȃ���Ȃ�
let (decoded, _, _) = encoding.decode(buffer);
(encoding, decoded.into_owned())
}
/// �o�̓t�@�C�����̐��� (SortedGemini ��t�^)
fn create_output_path (path: &Path) -> PathBuf {
let stem = path.file_stem().unwrap_or_default().to_str().unwrap_or_default();
let extension = path.extension().unwrap_or_default().to_str().unwrap_or_default();
let �V�t�@�C���� = if extension.is_empty() {
format! ("{}SortedGemini", stem)
} else {
format! ("{}SortedGemini.{}", stem, extension)
};
path.with_file_name(�V�t�@�C����)
}
�e�L�X�g�E�t�@�C�����s�\�[�g Claude
�@ChatGPT �Ɠ������Ƃ� Claude�i�N���[�h�j �ɕ��������ʁA���L�̃R�[�h�����Ă��܂����BGemini �ɋ����Ă�������R�[�h ���Q�Ɖ������BLineSortClaude
[package]
name = "LineSortClaude"
version = "0.1.0"
edition = "2024"
[dependencies]
native-dialog = "0.7" # �n�Ӓ��F���̃_�C�A���O�̃o�[�W�������グ�� �� FileDialog::new() ���g���Ȃ��ăG���[�ɂȂ�܂�
# native_dialog::FileDialog �ł͂Ȃ� rfd ::FileDialog ���g����������
encoding_rs = "0.8.35"
�@main.rs
use std ::fs::{File, OpenOptions};
//use std::io::{BufReader, BufWriter, Read, Write};
use std ::io::{BufWriter, Read, Write};
use std ::path::{Path, PathBuf };
//use encoding_rs::{SHIFT_JIS, UTF_8, UTF_16LE, UTF_16BE};
use encoding_rs ::{SHIFT_JIS, UTF_16LE, UTF_16BE};
use std ::{time, io}; //���ԁiDuration , Instant�j�ƕW�����o��
fn main() {
if let Err(e) = run() {
eprintln! ("�G���[���������܂���: {}", e);
std::process::exit(1);
}
}
run() -> Result<(), Box<dyn std::error::Error>> {
// �t�@�C���I���_�C�A���O��\��
let file_path = select_file() ?;
// ���̎����i�v���J�n�n�_�j���擾
let now = time::Instant::now();
println! ("�I�����ꂽ�t�@�C��: {}", file_path.display());
// �t�@�C����ǂݍ��݁A�G���R�[�f�B���O���������o
let (lines, encoding, has_bom) = read_file_with_encoding(&file_path)?;
println! ("���o���ꂽ�G���R�[�f�B���O: {:?}", encoding);
println! ("�ǂݍ��s��: {}", lines.len());
// �N�C�b�N�\�[�g�ōs���\�[�g
let mut sorted_lines = lines;
quick_sort (&mut sorted_lines);
println! ("�\�[�g����");
// �o�̓t�@�C������
let output_path = generate_output_path(&file_path)?;
println! ("�o�͐�: {}", output_path.display());
// �\�[�g���ʂ��t�@�C���ɏ�������
write_file_with_encoding(&output_path, &sorted_lines, encoding, has_bom)?;
println! ("�t�@�C���̏������݂��������܂���");
// �ŏ��̎�������̌o�ߎ��Ԃ�\��
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration �^�j
let elapsed = now.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let total_secs = elapsed.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let hours = total_secs / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let minutes = (total_secs % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let seconds = total_secs % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut output = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if hours > 0 {
output.push_str(&format! ("{}����", hours));
}
// �u���v��0���傫����Ε\���ɒlj�
if minutes > 0 {
output.push_str(&format! ("{}��", minutes));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if seconds > 0 {
output.push_str(&format! ("{}�b", seconds));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if output.is_empty() {
output.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println! ("�o�ߎ���: {}", output);
// �W�����͂�ҋ@
println! ("");
let mut input = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut input).unwrap();
Ok(())
}
select_file() -> Result<PathBuf , Box<dyn std::error::Error>> {
let file = native_dialog::FileDialog ::new()
.add_filter("�e�L�X�g�t�@�C��", &["txt", "csv", "log"])
.add_filter("���ׂẴt�@�C��", &["*"])
.show_open_single_file()?;
file.ok_or_else(|| "�t�@�C�����I������܂���ł���".into())
}
#[derive(Debug, Clone, Copy)]
enum DetectedEncoding {
Utf8,
Utf16Le,
Utf16Be,
ShiftJis,
}
fn read_file_with_encoding(path: &Path) -> Result<(Vec <String>, DetectedEncoding, bool), Box<dyn std::error::Error>> {
let mut file = File::open(path)?;
let mut bytes = Vec ::new();
file.read_to_end(&mut bytes)?;
// BOM�ƃG���R�[�f�B���O�̌��o
let (encoding, has_bom, start_pos) = detect_encoding(&bytes);
// �o�C�g����f�R�[�h
let text = decode_bytes(&bytes[start_pos..], encoding)?;
// �s�ɕ����iCRLF��LF�̗����ɑΉ��j
let lines: Vec <String> = text
.lines()
.map(|s| s.to_string())
.collect();
Ok((lines, encoding, has_bom))
}
fn detect_encoding(bytes: &[u8]) -> (DetectedEncoding, bool, usize) {
// BOM�`�F�b�N
if bytes.starts_with(&[0xEF, 0xBB, 0xBF]) {
return (DetectedEncoding::Utf8, true, 3);
}
if bytes.starts_with(&[0xFF, 0xFE]) {
return (DetectedEncoding::Utf16Le, true, 2);
}
if bytes.starts_with(&[0xFE, 0xFF]) {
return (DetectedEncoding::Utf16Be, true, 2);
}
// BOM�Ȃ��̏ꍇ�A���e���琄��
// UTF-16�̌��o�inull �o�C�g�̑��݂��`�F�b�N�j
let null_count = bytes.iter() .take(1000.min(bytes.len())).filter(|&&b| b == 0).count();
if null_count > 10 {
// �����ʒu��null�������ꍇ��UTF-16LE
let even_nulls = bytes.iter() .enumerate().take(1000.min(bytes.len()))
.filter(|&(ref i, &b)| i % 2 == 1 && b == 0).count();
// .filter(|(i, &b)| i % 2 == 1 && b == 0).count();
if even_nulls > null_count / 2 {
return (DetectedEncoding::Utf16Le, false, 0);
}
// ��ʒu��null�������ꍇ��UTF-16BE
let odd_nulls = bytes.iter() .enumerate().take(1000.min(bytes.len()))
.filter(|&(ref i, &b)| i % 2 == 0 && b == 0).count();
// .filter(|(i, &b)| i % 2 == 0 && b == 0).count();
if odd_nulls > null_count / 2 {
return (DetectedEncoding::Utf16Be, false, 0);
}
}
// UTF-8�̌��o
if std::str::from_utf8(bytes).is_ok() {
return (DetectedEncoding::Utf8, false, 0);
}
// �f�t�H���g��Shift_JIS
(DetectedEncoding::ShiftJis, false, 0)
}
fn decode_bytes(bytes: &[u8], encoding: DetectedEncoding) -> Result<String, Box<dyn std::error::Error>> {
match encoding {
DetectedEncoding::Utf8 => {
Ok(String::from_utf8_lossy(bytes).to_string())
}
DetectedEncoding::Utf16Le => {
let (decoded, _, had_errors) = UTF_16LE.decode(bytes);
if had_errors {
eprintln! ("�x��: �f�R�[�h���ɃG���[������܂���");
}
Ok(decoded.to_string())
}
DetectedEncoding::Utf16Be => {
let (decoded, _, had_errors) = UTF_16BE.decode(bytes);
if had_errors {
eprintln! ("�x��: �f�R�[�h���ɃG���[������܂���");
}
Ok(decoded.to_string())
}
DetectedEncoding::ShiftJis => {
let (decoded, _, had_errors) = SHIFT_JIS.decode(bytes);
if had_errors {
eprintln! ("�x��: �f�R�[�h���ɃG���[������܂���");
}
Ok(decoded.to_string())
}
}
}
quick_sort (arr: &mut [String]) {
if arr.len() <= 1 {
return;
}
//let len = arr.len();
let pivot_index = partition (arr);
let (left, right) = arr.split_at_mut(pivot_index);
quick_sort (left);
if right.len() > 1 {
quick_sort (&mut right[1..]);
}
}
partition (arr: &mut [String]) -> usize {
let len = arr.len();
let pivot_index = len / 2;
arr.swap(pivot_index, len - 1);
let mut i = 0;
for j in 0..len - 1 {
if arr[j] <= arr[len - 1] {
arr.swap(i, j);
i += 1;
}
}
arr.swap(i, len - 1);
i
}
fn generate_output_path (input_path: &Path) -> Result<PathBuf , Box<dyn std::error::Error>> {
let parent = input_path.parent().ok_or("�e�f�B���N�g����������܂���")?;
let stem = input_path.file_stem().ok_or("�t�@�C�������擾�ł��܂���")?;
let extension = input_path.extension().unwrap_or_default();
let �V�t�@�C���� = format! (
"{}SortedClaude.{}",
stem.to_string_lossy(),
extension.to_string_lossy()
);
Ok(parent.join(�V�t�@�C����))
}
fn write_file_with_encoding(
path: &Path,
lines: &[String],
encoding: DetectedEncoding,
has_bom: bool,
) -> Result<(), Box<dyn std::error::Error>> {
let file = OpenOptions::new()
.write(true)
.create(true)
.truncate(true)
.open(path)?;
let mut writer = BufWriter::new(file);
// BOM����������
if has_bom {
match encoding {
DetectedEncoding::Utf8 => writer.write_all(&[0xEF, 0xBB, 0xBF])?,
DetectedEncoding::Utf16Le => writer.write_all(&[0xFF, 0xFE])?,
DetectedEncoding::Utf16Be => writer.write_all(&[0xFE, 0xFF])?,
_ => {}
}
}
// �e�s���G���R�[�h���������
for (i, line) in lines.iter() .enumerate() {
let encoded = encode_string(line, encoding)?;
writer.write_all(&encoded)?;
// �Ō�̍s�ȊO�͉��s��lj��i���̃t�@�C���Ɠ����`���j
if i < lines.len() - 1 {
let newline = encode_string("\r\n", encoding)?;
writer.write_all(&newline)?;
}
}
writer.flush()?;
Ok(())
}
fn encode_string(s: &str, encoding: DetectedEncoding) -> Result<Vec <u8>, Box<dyn std::error::Error>> {
match encoding {
DetectedEncoding::Utf8 => Ok(s.as_bytes().to_Vec ()),
DetectedEncoding::Utf16Le => {
let (encoded, _, had_errors) = UTF_16LE.encode(s);
if had_errors {
eprintln! ("�x��: �G���R�[�h���ɃG���[������܂���");
}
Ok(encoded.to_Vec ())
}
DetectedEncoding::Utf16Be => {
let (encoded, _, had_errors) = UTF_16BE.encode(s);
if had_errors {
eprintln! ("�x��: �G���R�[�h���ɃG���[������܂���");
}
Ok(encoded.to_Vec ())
}
DetectedEncoding::ShiftJis => {
let (encoded, _, had_errors) = SHIFT_JIS.encode(s);
if had_errors {
eprintln! ("�x��: �G���R�[�h���ɃG���[������܂���");
}
Ok(encoded.to_vec())
}
}
}
eprintln! �F�W���o�͂ł͂Ȃ��A�W���G���[�ɃG���[���b�Z�[�W���������݂܂��Bhttps://ittrip.xyz/rust/rust-stderr-handling �e�L�X�g�Ɋ܂܂�镶���̕������̏o����
�@�T�㏬���V���[���b�N�E�z�[���Y�́u�x��l�`�v �ł́A�p���ł́A���� e �̏o�����ł��������Ƃ𗘗p���ĈÍ�����ǂ��Ă��܂��B�����R�[�h UTF-16 �Ńt�@�C���ۑ� ���Q�Ɖ������BCountOfEachCharacterJP
[package]
name = "CountOfEachCharacterJP"
version = "0.1.0"
edition = "2024"
[dependencies]
encoding_rs = "0.8.35"
rfd = "0.17.2"
�@main.rs
//ChatGPT �ɂ��
use encoding_rs ::{SHIFT_JIS, UTF_16BE, UTF_16LE, UTF_8};
use std ::collections::HashMap ;
use std::fs ;
use std ::io::Write;
use std ::path::Path;
use std ::io;
/// �o�C�g�當���R�[�h�肵�� UTF-8 String �ɕϊ�
fn utf8�ɕϊ�(bytes: &[u8]) -> String {
// UTF-8 BOM
if bytes.starts_with(&[0xEF, 0xBB, 0xBF]) {
let (cow, _, _) = UTF_8.decode(&bytes[3..]);
return cow.to_string();
}
// UTF-16 LE BOM
if bytes.starts_with(&[0xFF, 0xFE]) {
let (cow, _, _) = UTF_16LE.decode(&bytes[2..]);
return cow.to_string();
}
// UTF-16 BE BOM
if bytes.starts_with(&[0xFE, 0xFF]) {
let (cow, _, _) = UTF_16BE.decode(&bytes[2..]);
return cow.to_string();
}
// �� BOM ���� UTF-8 ������
let (cow, _, had_errors) = UTF_8.decode(bytes);
if !had_errors {
// UTF-8 �Ƃ��Ė��Ȃ���̗p
return cow.to_string();
}
// �Ō�� Shift JIS
let (cow, _, _) = SHIFT_JIS.decode(bytes);
cow.to_string()
}
// �@ �t�@�C���I���_�C�A���O
let �t�@�C��_�p�X = rfd ::FileDialog ::new()
.add_filter("Text", &["txt"])
.pick_file();
let path = match �t�@�C��_�p�X {
Some (p) => p,
None => {
println! ("�t�@�C�����I������܂���ł���");
return;
}
};
// �A �t�@�C���ǂݍ���
let bytes = fs:: read(&path).expect("�t�@�C���ǂݍ��ݎ��s");
// �����R�[�h���l������ UTF-8 �ɕϊ�
let text = utf8�ɕϊ�(&bytes);
// �B �������Ƃ̏o�����J�E���g�i�E���s���O�j
let mut �J�E���g: HashMap <char, usize> = HashMap ::new();
for ch in text.chars() {
if ch == ' ' || ch == '\n' || ch == '\r' || ch == '\t' {
continue;
}
*�J�E���g.entry(ch).or_insert(0) += 1 ;
}
// �o�̓t�@�C�����쐬
let stem = path.file_stem().unwrap().to_string_lossy();
let parent = path.parent().unwrap_or(Path::new("."));
let out_path = parent.join(format! ("{}Count.txt", stem));
// �C ���ёւ�
// 1. �o���̍~��
// 2. �o���������ꍇ�͕����R�[�h���i�����j
let mut items: Vec <(char, usize)> = �J�E���g.into_iter().collect();
items.sort_by (|a, b| {
b.1.cmp(&a.1) // �o���F������
.then_with(|| a.0.cmp(&b.0)) // �����R�[�h��
});
// �C UTF-8 �ŏ����o��
let mut out = fs:: File::create(&out_path).expect("�o�̓t�@�C���쐬���s");
for (ch, count) in items {
writeln!(out, "{}\t{}", ch, count).unwrap();
}
println! ("�����p�x���o�͂��܂���:");
println! ("{:?}", out_path);
// �W�����͂�ҋ@
println! ("");
let mut ���� = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
HashMap �Fhttps://maku77.github.io/p/eefwaa3/ https://terminart-express.site/archives/3265 https://labex.io/ja/tutorials/storing-key-value-pairs-with-rust-hash-maps-100408 https://doc.rust-jp.rs/book-ja/ch08-03-hash-maps.html https://doc.rust-jp.rs/rust-by-example-ja/std/hash.html https://keens.github.io/blog/2020/05/23/rustnohashmaphaentrygabenri/ sort_by https://ittrip.xyz/rust/rust-collection-sorting-guide#index_id10 https://dottrail.codemountains.org/rust-vec-sort-by/ https://vraisamis.hatenadiary.jp/entry/2019/08/09/022201 https://yiskw713.hatenablog.com/entry/rust-hashmap-sort https://sibainu.lsv.jp/rust-quicksort-revenge-2/ UTF-8 CSV �t�@�C����ǂ�Œ��o
�N�W����s�� ���ARust�ŗL���A���S���Y���ɒ��� �Ƃ����A�ڋL����������Ă��܂��B12���s�̃e�L�X�g����������v���O���������₷���E���x�E�������̊ϓ_�������Ă݂悤 �Ƃ����L��������܂����B�Z���̗X�֔ԍ��i1���R�[�h1�s�AUTF-8�`���j�iCSV�`���j https://www.post.japanpost.jp/zipcode/dl/utf-zip.html Gemini �Ɉ˗����āACSV�t�@�C���̑I���̓t�@�C�����J���_�C�A���O���g���悤�ɁA�����āA�\���������ʂ̉�ʂ���Ȃ��悤�ɕύX���Ă�������R�[�h���A�]�ڂ����Ă��������܂��B
[package]
name = "sort_simple_Kujira"
version = "0.1.0"
edition = "2021"
[dependencies]
rfd = "0.15"
main.rs
// sort_simple_Kujira
// ������͂��
// http://kujirahand.com/
// https://news.mynavi.jp/techplus/article/rustalgorithm-34/
// Rust�ŗL���A���S���Y���ɒ���
// 12���s�̃e�L�X�g����������v���O���������₷���E���x�E�������̊ϓ_�������Ă݂悤
std::env; // ���s�t�@�C���̓o�^�t�H���_���擾���邽��
use rfd::FileDialog;
use std::fs::File;
use std::io::{BufRead, BufReader};
use std::error::Error;
use std::io;
fn main() -> Result<(), Box<dyn Error>> {
// �t�@�C���_�C�A���O
// exe�i���s�t�@�C���j�̃p�X���擾���A���̐e�f�B���N�g���i�t�H���_�j���擾
let mut dialog = FileDialog::new().add_filter("CSV File", &["csv"]);
// exe�̏ꏊ������Ɏ擾�ł����ꍇ�̂݁A�����t�H���_��ݒ肷��
if let Ok(exe_path) = env ::current_exe() {
if let Some(exe_dir) = exe_path.parent() {
dialog = dialog.set_directory(exe_dir); // �������t�H���_���w��
}
}
// �t�@�C�����J���_�C�A���O
let ���̓p�X = dialog
.pick_file()
.ok_or("�t�@�C�����I������܂���ł����B")?;
// �Ώ�CSV�t�@�C�����J����BufReader�œǂ�
//CSV�t�@�C�����J���āABufReader���g���ăf�[�^��ǂݏo���܂��B
//�uFile::open�v�̓t�@�C�����J�����\�b�h�ŁA�u?�v���g�����ƂŃG���[�������Ȍ��ɋL�q���܂��B
//let file = File::open("utf_ken_all.csv")?;
let file = File::open(���̓p�X)?;
let reader = BufReader::new(file);
// �Z���J�i��X�֔ԍ��E�Z�����ꎞ�ۑ�����\���̂�������
let mut entries = Vec ::new();
// 1�s���ǂݍ���� CSV�t�B�[���h�𒊏o
for line in reader.lines() {
let line = line?;
if line.is_empty() {
continue;
}
// �t�B�[���h�����ăg�������A�K�v�ȏ��𒊏o
//1�s�̕�������J���}���ŕ������ACSV�̊e�t�B�[���h�����o���Ă��܂��B
//CSV�ł͒l�� "������" �̂悤�Ƀ_�u���N�H�[�g�ň͂܂�Ă��邱�Ƃ��������߁A
//�t�B�[���h�O��̃_�u���N�H�[�g�u"�v����菜���āAString�ɕϊ����܂��B
let fields: Vec <String> = line
.split(',')
.map(|s| s.trim_matches('"').to_string())
.collect();
// �Z���J�i(5��6��)�A�X�֔ԍ�(3���)�A�Z��(8��9���)���擾
let kana_key = format!("{}{}",
fields.get(4).map(String::as_str).unwrap_or(""),
fields.get(5).map(String::as_str).unwrap_or(""));
let postal = fields.get(2).map(String::as_str).unwrap_or("").to_string();
let address = format!("{}{}",
fields.get(7).map(String::as_str).unwrap_or(""),
fields.get(8).map(String::as_str).unwrap_or(""));
// ���o���������^�v���Ƃ��ăx�N�^�ɒlj�
//�^�v�� �Ƃ���Vec �^�� entries �ɒlj����܂��B
//�^�v����(�Z���J�i, �X�֔ԍ�, �Z��)�ƂȂ��Ă��܂��B
entries.push((kana_key, postal, address));
}
// �Z���J�i���L�[�ɏ����\�[�g���A�擪5�����o��
//�f�[�^���Z���J�i���L�[�ɂ��ď����\�[�g���āA�擪��5����\�����܂��B
//�|�C���g�́AVec �^�� entries ���Asort_by���\�b�h �Ń\�[�g���Ă��镔���ł��B
//sort_by�̈����ɂ̓N���[�W��(������)���w�肵�Ă��܂��B
//�����ł́AVec �^�� entries �ɂ̓^�v���������Ă���̂ŁA
//�^�v���̐擪�̗v�f(a.0��b.0)���r���邱�ƂŁA�J�i���ɕ��ёւ��ł��܂��B
entries.sort_by (|a, b| a.0.cmp(&b.0));
for (_, postal, address) in entries.iter().take(5) {
println!("{} {}", postal, address);
}
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line(&mut ����).unwrap();
Ok(())
}
���������Ă݂����́F
[package]
name = "sort_simple2_Kujira"
version = "0.1.0"
edition = "2021"
[dependencies]
rfd = "0.15"
main.rs
// sort_simple2_Kujira
// ������͂��
// http://kujirahand.com/
// https://news.mynavi.jp/techplus/article/rustalgorithm-34/
// Rust�ŗL���A���S���Y���ɒ���
// 12���s�̃e�L�X�g����������v���O���������₷���E���x�E�������̊ϓ_�������Ă݂悤
//���������Ă݂����́F
use std::env; // ���s�t�@�C���̓o�^�t�H���_���擾���邽��
use rfd::FileDialog;
use std::fs::File;
use std::io::{self, Read, Write};
use std::error::Error;
// use std::io;
fn main() -> Result<(), Box<dyn Error>> {
// �t�@�C�����ۂ��Ɠǂݍ��݁A�㑱�Ńt�B�[���h�Q�Ƃ��o��
let mut data = Vec ::new();
// �t�@�C���_�C�A���O
// exe�i���s�t�@�C���j�̃p�X���擾���A���̐e�f�B���N�g���i�t�H���_�j���擾
let mut dialog = FileDialog ::new().add_filter("CSV File", &["csv"]);
// exe�̏ꏊ������Ɏ擾�ł����ꍇ�̂݁A�����t�H���_��ݒ肷��
if let Ok(exe_path) = env::current_exe() {
if let Some(exe_dir) = exe_path.parent() {
dialog = dialog.set_directory(exe_dir); // �������t�H���_���w��
}
}
// �t�@�C�����J���_�C�A���O
let ���̓p�X = dialog
.pick_file()
.ok_or("�t�@�C�����I������܂���ł����B")?;
// �t�@�C���S�̂�ǂݍ���
File::open(���̓p�X)?.read_to_end(&mut data)?;
if !data.ends_with(b"\n") {
data.push(b'\n');
}
// �s���ڈ������ƂɑO��肵�ă������A���P�[�V������}��
let estimated_rows = 150_000; // �X�փf�[�^�s���ڈ�
let mut entries: Vec <Entry<'_>> = Vec ::with_capacity(estimated_rows);
// �o�C�g��𑖍����ăJ���}�ʒu��T���A�K�v�t�B�[���h�����X���C�X�擾
let mut start = 0;
let mut col = 0;
let mut fields: [&str; 9] = [""; 9];
for i in 0..data.len() {
let b = data[i];
if b == b',' || b == b'\n' {
if col < 9 {
let field_bytes = &data[start..i];
// CSV�̃_�u���N�H�[�g�͕s�v�Ƃ̑O��Ȃ̂Ńg�����݂̂őΉ�
let field = trim_quotes(field_bytes);
fields[col] = field;
}
col += 1;
start = i + 1;
if b == b'\n' {
if col >= 9 {
// �Z���J�i(5,6��), �X�֔ԍ�(3��), �Z��(8,9��)
entries.push(Entry {
kana1: fields[4],
kana2: fields[5],
postal: fields[2],
addr1: fields[7],
addr2: fields[8],
});
}
// ���Z�b�g
col = 0;
fields = [""; 9];
}
}
}
// �Z���J�i���L�[�ɏ����ŏ��5���������I�����ďo��
let cmp = |a: &Entry, b: &Entry| match a.kana1.cmp(b.kana1) {
std::cmp::Ordering::Equal => a.kana2.cmp(b.kana2),
other => other,
};
let k = entries.len().min(5);
if k > 0 {
// �����I���Ő擪k���͈̔͂������m�肳����
entries.select_nth_unstable_by(k - 1, cmp);
// �K�v�Ȑ擪k���݂̂�����E�����Ƀ\�[�g
entries[..k].sort_unstable _by(cmp);
let mut stdout = std::io::BufWriter::new(std::io::stdout());
for entry in entries.iter().take(k) {
writeln!(stdout, "{} {}{}", entry.postal, entry.addr1, entry.addr2)?;
}
}
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line(&mut ����).unwrap();
Ok(())
}
#[derive(Debug, Clone, Copy)]
struct Entry<'a> {
kana1: &'a str,
kana2: &'a str,
postal: &'a str,
addr1: &'a str,
addr2: &'a str,
}
// �_�u���N�H�[�g���O����UTF-8������֕ϊ�
fn trim_quotes(bytes: &[u8]) -> &str {
let mut s = bytes;
if s.starts_with(b"\"") && s.ends_with(b"\"") && s.len() >= 2 {
s = &s[1..s.len() - 1];
}
std::str::from_utf8(s).unwrap_or("")
}
�f��������
�P�D�f��������(��������@)
factorization3JP.rs �����C�y Rust �v���O���~���O������̃R�[�h �Ɏ�����������̂ł�rustc factorization3JP.rs �ŃR���p�C���ł��܂��B
// �f��������
// rustc factorization3JP.rs
use std ::{time, io};
//use std ::io;
fn �f��������(n: u128 ) {
// ���̎������擾
let �J�n���� = time::Instant::now();
println! ("{}",n);
fn �f���������T�u(n: u128, m: u128) -> (u128, u128) {
let mut c = 0;
let mut x = n;
while x % m == 0 {
c += 1;
x /= m;
}
(c, x)
}
let (c, n) = �f���������T�u(n, 2);
if c > 0 { print!("({},{})", 2, c); }
let mut x = 3;
let mut m = n;
while x * x <= m {
let (c, n) = �f���������T�u(m, x);
if c > 0 { print!("({},{})", x, c); }
m = n;
x += 2;
}
if m > 1 { print!("({},{})", m, 1); }
println! ("");
// �ŏ��̎���������o�ߎ��Ԃ�\��
println! ("{:?}", �J�n����.elapsed());
println! ("");
}
fn main() {
�f��������(24);
�f��������(12345678);
�f��������(123456789);
�f��������(1234567890);
�f��������(1111111111);
�f��������(8635844967113809);
�f��������(121439531096594251777);
println! ("����10���Ԃ�����܂��I");
println! ("�҂ĂȂ��Ȃ�E�C���h�E�E��́~�ŏI�����Ă��������B");
�f��������(717985416201895737890248682491); //10��6���� 886851/(60*60*24)=10.264479166667
// �W�����͂�ҋ@
println! ("");
let mut ���� = String::new();
println! ("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
���ꂼ��̍ŏ��l�ő�l �́A�E�̉摜���Q�Ɖ������B38�� �܂Ńt���ɕ\���ł��܂��I�Ihttps://sagecell.sagemath.org/ https://pari.math.u-bordeaux.fr/gpwasm.html https://keisan.casio.jp/exec/user/1380353934 �Q�D�f��������(���C�u�����g�p)
prime_factorization ������܂��BGemini �ɋ����Ă���������C�u�����𗘗p�����f���������v���O�����ł��Bnum-bigint ���C�u�����ȂǂƑg�ݍ��킹�Ďg���̂� Rust �ł̈�ʓI�ȗ���ɂȂ�܂��B
[package]
name = "PrimeFactorization"
version = "0.1.0"
edition = "2021"
[dependencies]
prime_factorization = "1.0.5"
// PrimeFactorization
// Gemini �ɋ����Ă��炢�܂���
// https://crates.io/crates/prime_factorization
// https://docs.rs/prime_factorization/latest/prime_factorization/
// �ő�128�r�b�g�����܂ł̑f�����������C�u�����B
//���������A���S���Y���́A�ŏ��� 1000 �̑f���ɂ�鎎������A�t�F���}�[�̈�������@�A
//�����Đ{�R�̔}��ϐ�����p�����ˉe���W��p���������X�g���̑ȉ~�Ȑ�������������\������܂��B
//�t�F���}�[�̈�������@�̌�A�ȉ~�Ȑ����������̃X�e�b�v�ɐi�ޑO�ɁA
//���̐����f���ł���\�����A���̑傫���ɉ�����
//�~���[�E���r���@�܂��͋����x�C���[-PSW �f������@�̂����ꂩ��p���Ĕ��肵�܂��B
//��҂̔���@�́A�����Ŏg�p����Ă��鐔�l�͈� (128 �r�b�g�܂�) �ł͌���_�I�ł͂���܂��A
//���m�̔���͑��݂��܂���B
//Miller-Rabin�f�������Baillie-PSW�f������͊m���I�Ȕ���ł����A
//���̃v���O�������g�p���鐔�l�͈͂ł͔��Ⴊ���݂��܂���B
//�ȉ~�Ȑ����������ł́A�Ȑ���̃����_���ȏ����_���g�p���邽�߁A
//���s���Ԃɑ����̂����������\��������܂��B
use std::time; // ���ԁiDuration, Instant�j���g������
use std::io; // ���͂̂��߂̃C���|�[�g
use prime_factorization ::Factorization;
use std::collections::BTreeMap ; // �lj��F���𐔂��邽�߂̃}�b�v
use std::io::{Write}; // �o�͂̂��߂̃C���|�[�g
fn main() {
// 1. �f�����������������i���f���j���`
// = 103,979 * 36,028,797,018,963,913
// ���f���isemiprime�j�Ƃ́A�Q�̑f���̐ςŕ\����鎩�R��
let num: u128 = 3_746_238_285_234_848_709_827;
// 2. �f�������������s
let factor_repr = Factorization::run(num);
// 3. �擾�����f�����̃��X�g��\��
// {:?} �̓f�o�b�O�\���p�̃t�H�[�}�b�g�ł�
println!("���̐�: {}", num);
println!("�f���������̌���: {:?}", factor_repr.factors);
// 4. �����ƈ�v���邩�`�F�b�N
assert_eq!(factor_repr.factors, Vec ![103_979, 36_028_797_018_963_913]);
println!("���ɐ������܂����I");
println!("");
// 1. �f�������������������`
let num: u128 = 717_985_416_201_895_737_890_248_682_491;
// 2. �f�������������s
let factor_repr = Factorization::run(num);
// 3. �擾�����f�����̃��X�g��\��
// {:?} �̓f�o�b�O�\���p�̃t�H�[�}�b�g�ł�
println!("���̐�: {}", num);
println!("�f���������̌���: {:?}", factor_repr.factors);
println!("���҂��錋�ʁ@�@�F7 * 59 * 1738463477486430358087769207");
println!("");
// ---------------------------------------
//���[�U�[�����͂���������f������������C���^���N�e�B�u�ȃv���O����
println!("--- �f���������c�[�� (u128 �Ή��A���w�`���\��) ---");
println!("�ő�38���̐����܂œ��͂ł��܂��B�傫�ȑf���̐ς͎��Ԃ�������܂��B");
println!("10��18���1 �F 1010101010101010101010101010101010101 ������������܂�(^^�U");
println!("�I������ɂ� 'q' ����͂��邩�ACtrl+C �������Ă��������B");
loop {
// 1. �v�����v�g�i���͑҂��̍��}�j��\��
print!("\n������������������͂��Ă�������: ");
io::stdout().flush().unwrap(); // �\�����m�肳����iWindows�ŕK�v�ɂȂ邱�Ƃ�����
// 2. ���[�U�[�̓��͂�ǂݎ��
let mut input = String::new();
io::stdin()
.read_line(&mut input)
.expect("���͂̓ǂݎ��Ɏ��s���܂���");
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// 3. �I������
let input = input.trim(); // ���s�R�[�h����菜��
if input == "q" {
println!("�I�����܂��B");
break;
}
// 4. ������𐔒l�iu128�j�ɕϊ�
match input.parse::<u128>() {
Ok(num) => {
// �f�������������s
let factor_repr = Factorization::run(num);
// --- �������琔�w�`���ւ̕ϊ����W�b�N ---
// 1. �e�f�����̌����W�v (��: [3, 3, 5] -> {3: 2, 5: 1})
let mut counts = BTreeMap ::new();
for &f in &factor_repr.factors {
*counts.entry(f).or_insert(0) += 1 ;
}
// 2. �\���p�̕�����ɐ��`
let result_parts: Vec <String> = counts
.iter()
.map(|(&base, &exp)| {
if exp > 1 {
format! ("{}^{}", base, exp) // �w���`��
} else {
base.to_string() // ���̂܂�
}
})
.collect();
// 3. " * " �łȂ��ĕ\��
println!("{} = {}", num, result_parts.join(" * "));
// ---------------------------------------
// 4. ���Z ---
// factor_repr.factors �́A�Ⴆ�� `12` ����͂����ꍇ�A [2, 2, 3] �̂悤�ȑf�����̃f�[�^�������Ă��܂��B
// �u.iter() .product()�v ���g���ƁA���X�g�̒��g��S�Ċ|���Z���Ă���܂��B
// `.iter() ` �Ńf�[�^�����ԂɎ��o���A`.product()` �ł�����S�Ċ|�����킹�܂��B
// �蓮�� `for` ���[�v�������Ċ|���Z����K�v���Ȃ��ARust �炵���X�}�[�g�ȏ������ł��B
let calculated_product: u128 = factor_repr.factors.iter() .product();
println!("---------------------------------------");
println!("���Z(Verification):");
println!(" �f�������X�g: {:?}", factor_repr.factors); // �f�̃��X�g��\��
// `{:?}` ���g�����ƂŁA�x�N�^�i���X�g�j�̒��g���f�o�b�O�`���i`[2, 2, 3]` �̂悤�Ȍ`�j��
// ���̂܂ܕ\�������Ă��܂��B���ۂɂǂ̐������|�����킳�ꂽ�̂������o�I�ɂ킩��܂��B
println!(" �Čv�Z���� : {}", calculated_product); // �|�����킹������
if num == calculated_product {
println!(" ���� : OK (���̐��l�ƈ�v���܂���)");
} else {
println!(" ���� : NG (�s��v)");
}
println!("---------------------------------------");
}
Err(_) => println!("�L���Ȑ��̐�������͂��Ă��������B"),
}
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration�^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let ���� = ���v�b�� / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let �� = (���v�b�� % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let �b = ���v�b�� % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut �o�� = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if ���� > 0 {
�o��.push_str(&format! ("{}����", ����));
}
// �u���v��0���傫����Ε\���ɒlj�
if �� > 0 {
�o��.push_str(&format! ("{}��", ��));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if �b > 0 {
�o��.push_str(&format! ("{}�b", �b));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if �o��.is_empty() {
�o��.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println!("�o�ߎ���: {}", �o��);
}
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line (&mut ����).unwrap();
}
prime_factorization ::Factorization; ���C�u���� prime_factorization �̒�����A��v�ȋ@�\������ Factorization �Ƃ����\���̂��g����悤�ɓǂݍ���ł��܂��Bhttps://crates.io/crates/prime_factorization https://docs.rs/prime_factorization/latest/prime_factorization/ Vec �j�������Ă��܂��BVec ![...]); ����́u���ӂƉE�ӂ���v���邩�v���m�F���閽�߂ł��B.iter() �F�J�Ԃ�Iterator �̊e�탁�\�b�h https://nossie531.github.io/doc/rust/iterator_methods.xhtml �C�e���[�^����܂Ƃ߁b�悭�g��16�̃��\�b�h https://zenn.dev/ha_maya0104/articles/6cb18e99c5edbd io::stdin().read_line (&mut input)match input.parse::<u128>()BTreeMap ���g���ƁA���������Ɏ����ŕ��בւ��A�����J�E���g���Ă���܂��BHashMap �ł͂Ȃ� BTreeMap ���g���̂��|�C���g�ł��Bhttps://doc.rust-lang.org/std/collections/struct.BTreeMap.html Entry API �j�ł��Bhttps://keens.github.io/blog/2020/05/23/rustnohashmaphaentrygabenri/ match �ɂ��G���[�n���h�����O�i���S�Ƀv���O���������R�c�jhttps://sehermitage.web.fc2.com/devel/rust_bigint.html https://crates.io/crates/num-bigint https://docs.rs/num-bigint/latest/num_bigint/ �R�D�f��������(PARI/GP�g�p)
PARI/GP �Ƃ����v�Z�@�㐔�A�v���P�[�V�� ��������A�����_ (���������A �㐔�I�����_�A�ȉ~�Ȑ���) �ɂ�����v�Z�������ɍs�Ȃ����Ƃ��ł��܂��B������g�����f���������̃v���O���� �����s���Ă݂܂����BGemini �� Rust �� PARI/GP �𗘗p�ł��Ȃ����ƕ������Ƃ���Acall_gp ` �Ƃ������ɂ܂Ƃ߂Ă���܂��B����ɂ��A�u�f���������̂��߂� GP ���Ăԁv�u���Z�̂��߂� GP ���Ăԁv�Ƃ���2��̌Ăяo�����X�b�L���L�q����Ă��܂��B`u128` �Ȃǂ̐��l�^ ���g�킸�A���ׂāu������iString�j�v�Ƃ��Ĉ����Ă��邽�߁A**���_��̓��������������艽�猅�ł�** �G���[�ɂȂ炸�ɏ����ł���̂����̃v���O�����̍ő�̋��݂ł��BRSA-100 = 1522605027922533360535618378132637429718068114961380688657908494580122963258952897654000350692006139 ���ł��܂����I�I�f��������(msieve �g�p) ���� 3���Ԃł����B)https://pari.math.u-bordeaux.fr/download.html
�@
PARI/GP �̃I�v�V����
�R�}���h���C���E�I�v�V�����́A�Z�k�`(-f)��POSIX�Ɏ����`(--fast)�̗����ŗ��p�ł��܂��Bk(�L��) �AM(���K) �AG(�M�K) ��t���邱�Ƃ��ł��܂��B���̏ꍇ�A�����͂��ꂼ�� 10^3 �A10^6�A10^9 �|�����܂��B
-f, --fast
�����X�^�[�g(�܂��͍H��o���ݒ�)�B�N������.gprc (gprc.txt)��ǂݍ��݂܂���B
-p limit
[��] �N�����ɁAgp�͐��_�I���p�Ŏg�p����鏬���ȑf���̃e�[�u�����v�Z���܂��Bprimelimit(�f���Ɍ�) ���ݒ肳��Ă���ꍇ�A�e�[�u���ɂ̓f�t�H���g(= 500000)�ł͂Ȃ��A���̏���܂ł̑f�����܂܂�܂��B���݂ł́A���̒l��ύX���邱�Ƃ͂قƂ�LjӖ�������܂���B
-q, --quiet
�Ïl���[�h�B�w�b�_�[�◚��ԍ���\�������A����Ȃ�������܂���B
-D, --default key=val
�N�����ɁAdefault(key, val) �����s���āA
GPRC �̐ݒ�t�@�C���̒l���㏑�����܂��B
-s limit �N�����Ɋ��蓖�Ă��� gp �̓����X�^�b�N�̃T�C�Y�Bthe PARI stack overflows ! default(parisize, limit)���g���đ��₷���Ƃ��ł��܂��B
.gprc(gprc.txt) �� parisize ��ݒ肷��ƁA�Z�b�V�����Ԃʼni���I�ɗ��p�ł��܂��Bparisizemax �� .gprc ���Ő��́A���傫�Ȓl�ɐݒ肷�邱�Ƃ𐄏����܂�(�}�V�����ς�����Ǝv����l�A�ʏ�͎g�p�\�� RAM �̔������x)�B������ �X�^�b�N�ł̌v�Z�́A�f�[�^�̋Ǐ��������シ�邽�ߌ����I�ł��邱�Ƃɒ��ӂ��Ă��������Bthreadsize �� threadsizemax �́A����� gp �œ��l�̖������ʂ����܂��B
--emacs
gp �� Emacs �V�F���Ŏ��s�\�ł�(�ڍׂ�GP���[�U�[�}�j���A�����Q��)�BEmacs �Z�b�V�����O�Őݒ肷��ƃf�B�X�v���C�ُ̈킪�������܂��B
--help
���p�\�ȃR�}���h���C���I�v�V�����̊T�v��\�����܂��B
--test
GP ���e�X�g���[�h�Ŏ��s���܂� : ����ԍ��̕\����}�����A�����o�͍s��܂�Ԃ��܂�(�ǂ݂₷�������o�͂邽��)�B�x���`�e�X�g��p�ł��B
--texmacs
gp �� TeXmacs �̃t�����g�G���h������s�\�ł��B
--version
�o�[�W�������(�o�i�[)���o�͂��ďI�����܂��B
--version-short
�o�[�W�����ԍ����o�͂��ďI�����܂��B
[package]
name = "PrimeFactorizationPARI_GP"
version = "0.1.0"
edition = "2024"
[dependencies]
regex = "1"
main.rs
// PrimeFactorizationPARI_GP
// Gemini �ɋ����Ă��炢�܂���
// PARI/GP �� WEB �f�� Try PARI/GP in your browser
// https://pari.math.u-bordeaux.fr/gpwasm.html
//PARI/GP �� C���ꃉ�C�u���� (`libpari`) �� Windows �� Rust �Œ��ڃr���h�E�����N����̂�
//��Փx�������A�G���[�̉����ɂȂ肪���ł��B
//�����ŁA**�ł��m���ŊȒP�ȕ��@**������Ă��܂��B
//����́A**�uWindows �� PARI/GP (gp.exe) ���C���X�g�[�����A
//Rust ����R�}���h�Ƃ��ČĂяo���v**�Ƃ������@�ł��B
//����Ȃ畡�G�Ȑݒ�Ȃ��ɁAPARI/GP �̔����G���W���𗘗p�ł��܂��B
//���̃v���O�����́A���� `gp` �R�}���h�����s���A�f���������� `factor(����)` �Ƃ����v�Z���s�킹�A
//���̌��ʁA�f�����ƌ��i��: `[3, 2; 5, 1]`�j�� Rust �ʼn�͂��ĕ\�����܂��B
use std::time; // ���ԁiDuration, Instant�j���g�����߂̃��W���[��
//use std::io; // ���͂̂��߂̃C���|�[�g
use std::io::{self, Write}; // ���o�͂̂��߂̃C���|�[�g
use std::process::{Command, Stdio}; // Stdio ��lj�
//* �O���R�}���h�igp�j�ƃf�[�^������肷�邽�߂̃p�C�v�@�\���g�����߂ɕK�v
// `gp` �Ɍv�Z�����邽�߂ɂ́A**�u�W�����́istdin�j�v�Ɍv�Z���𗬂�����** �K�v������܂��B
use regex ::Regex; // Rust ���� `gp` �R�}���h�̏o�͂������₷�����邽�߂ɁA���K�\�����g��
fn main() {
println!("--- PARI/GP �f�������� & ���Z�c�[�� ---");
// ---------------------------------------
println!("");
println!("�f�����������鐔�i���f���j�̗�");
println!("3746238285234848709827");
println!("���f���isemiprime�j�Ƃ́A�Q�̑f���̐ςŕ\����鎩�R��");
println!("---------------------------------------");
println!("�f�����������鐔�̗�");
println!("717985416201895737890248682491");
println!("---------------------------------------");
println!("10��18���1�F1010101010101010101010101010101010101");
println!("---------------------------------------");
println!("50���F12345678901234567890123456789012345678901234567890");
println!("---------------------------------------");
println!("");
// ---------------------------------------
println!("(�I������ɂ� 'q' ����͂��Ă�������)");
// PARI/GP �̏o�͌`�� [�f��, �w��; �f��, �w��; ...] ����͂��邽�߂̐��K�\��
// ��: [3, 2; 5, 1] -> (3, 2), (5, 1) "3", "2" �� "5", "1"
let re = Regex ::new(r"(\d+),\s*(\d+)").unwrap();
loop {
print!("\n���������(38���ȏ����): ");
io::stdout().flush().unwrap();
let mut input = String::new();
io::stdin().read_line(&mut input).expect("�Ǎ����s");
let input_str = input.trim();
if input_str == "q" {
break;
}
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// ���l�`�F�b�N�A���͂����l�݂̂ō\������Ă��邩�ȈՃ`�F�b�N
if input_str.is_empty() || !input_str.chars().all(|c| c.is_ascii_digit()) {
println!("�L���Ȑ��l����͂��Ă��������B");
continue;
}
// ---------------------------------------------
// 1. �f���������̎��s
// ---------------------------------------------
let factor_cmd = format! ("print(factor({}));", input_str);
match call_gp (&factor_cmd) {
Ok(gp_output) => {
// --- ��͂ƕ\���p�̕�����ɐ��`���W�b�N ---
// ��͌��ʂ��i�[����x�N�^ [(�f��, �w��), ...]
let mut factors : Vec <(String, String)> = Vec ::new();
for cap in re.captures_iter(&gp_output) {
factors .push((cap[1].to_string(), cap[2].to_string()));
}
if factors .is_empty() {
// �f������������Ȃ��A�܂���1�Ȃǂ̏ꍇ
// gp_output ���̂�\�����Ċm�F�ł���悤�ɂ���
println!("����: {}", gp_output);
continue;
}
// ---------------------------------------------
// 2. ���ʂ̕\�� (���w�`���ɐ��`)
// ---------------------------------------------
let display_parts: Vec <String> = factors .iter()
.map(|(base, exp)| {
if exp == "1" {
base.clone()
} else {
format! ("{}^{}", base, exp)
}
})
.collect();
let result_string = display_parts.join(" * ");
println!("��������: {} = {}", input_str, result_string);
println!("---------------------------------------");
// ---------------------------------------------
// 3. ���Z (Verification)
// ---------------------------------------------
// ���Z�p�̎����쐬 (��: "3^2 * 5^1")
// GP�Ɍv�Z�����邽�߁A�w����1�ł� "^1" �����Ė����I�ɏ����`���ɂ��܂�
let calc_parts: Vec <String> = factors .iter()
.map(|(base, exp)| format! ("{}^{}", base, exp))
.collect();
let verify_formula = calc_parts.join(" * ");
// �쐬�������� GP �ɓ����Čv�Z������
let verify_cmd = format! ("print({});", verify_formula);
print!("���Z��... ");
io::stdout().flush().unwrap();
match call_gp (&verify_cmd) {
Ok(calc_result) => {
if calc_result == input_str {
println!("OK!");
println!("���؎� : {} = {}", verify_formula, calc_result);
} else {
println!("NG!");
println!("�s��v����: ���̐�[{}] != �v�Z����[{}]", input_str, calc_result);
}
},
Err(e) => println!("���Z�G���[: {}", e),
}
},
Err(e) => println!("GP���s�G���[: {}", e),
}
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration�^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// �ŏI�I�Ȍ��ʂ�\��
println!("�o�ߎ���: {} �b", ���v�b��);
}
// �W�����͂�ҋ@
println!("");
let mut ���� = String::new();
println!("Enter �ʼn�ʂ���܂�...");
io::stdin().read_line(&mut ����).unwrap();
}
// PARI/GP (gp.exe) ���Ăяo���Č��ʂ���ŕԂ���
// ���l����������A"�f���������̌��ʕ�����" ��Ԃ��܂�
// �R�}���h���C�������ŃX�^�b�N�T�C�Y���������Ă��܂�
// `gprc.txt` �Ɉˑ������A�v���O�������Łu���̂��炢�̃��������g���Ă���v�Ǝw�����܂��B
// GP �ɂ� `-s` �I�v�V����������A����ŃX�^�b�N�T�C�Y���w�肵�܂��B
// RSA-100�i���J���Í������̍l�Ď�3�l�iRivest�AShamir�AAdleman�j�̓������F100���j
// �̂悤�ȋ���Ȑ��������ꍇ�A�]�T�������� **256MB** ���x���蓖�Ă�ƈ��S�ł��B
fn call_gp (command_str: &str) -> Result<String, String> {
// 1. gp �v���Z�X�𗧂��グ��
let mut child = Command::new("gp")
.arg("-q") // quiet mode (�o�i�[��\�����Ȃ�)
// .arg("-f") // fast mode �y�폜�z ���ꂪ����� gprc.txt ��ǂݍ��݂܂���I
.arg("-s").arg("256M") // �y�lj��z �X�^�b�N�T�C�Y���I�� 256MB �Ɏw��
.stdin(Stdio::piped()) // Rust������͂𑗂��悤�ɂ���
.stdout(Stdio::piped()) // �o�͂�����悤�ɂ���
.spawn()
.map_err(|e| format! ("PARI/GP �N���Ɏ��s: {}", e))?;
{
// 2. gp �̕W������(stdin)�Ɍv�Z�R�}���h����������
// `gp -q -f` ���������s����
// ��: "print(factor(11111));\n" �𑗐M
let stdin = child.stdin.as_mut().ok_or("stdin���J���܂���")?;
stdin.write_all(command_str.as_bytes())
.map_err(|e| format! ("�������s: {}", e))?;
// �u���b�N����� child_stdin �� drop ����A���͏I���� gp �ɓ`���܂�
}
// 3. gp �̏�������(stdout)�����
let output = child.wait_with_output()
.map_err(|e| format! ("�Ǎ��Ɏ��s: {}", e))?;
if output.status.success() {
let res = String::from_utf8_lossy(&output.stdout);
Ok(res.trim().to_string())
} else {
let err = String::from_utf8_lossy(&output.stderr);
Err(err.trim().to_string())
}
}
���K�\�� (`Regex`) **:factors ` �x�N�^�ɓ����Ă��� `(�f��, �w��)` �̏����g���āARust ���Ŋ|���Z�̎��i������j��g�ݗ��Ă܂��i��: `"3^2 * 5^1"`�j�Bcall_gp ` �ɓn���APARI/GP �Ɍv�Z�����܂��B�S�D�f��������(�t�@�C�����͂�PARI/GP�g�p)
PARI/GP (gp.exe) �𗘗p����ƁA�傫�ȑf�����|�����킹�������̑������ł��A�����őf���������ł��� ���Ƃ�������܂����BGemini �ɋ����Ă��炢�܂����BPARI/GP �̑f���������𗘗p���Ď��s���܂��B
[package]
name = "gp_factorizer_file"
version = "0.1.0"
edition = "2021"
[dependencies]
regex = "1"
rfd = "0.12" # �t�@�C���_�C�A���O�p�̃��C�u����
// gp_factorizer_file
// Gemini �ɋ����Ă��炢�܂���
//PARI/GP �� C���ꃉ�C�u���� (`libpari`) �� Windows �� Rust �Œ��ڃr���h�E�����N����̂�
//��Փx�������A�G���[�̉����ɂȂ肪���ł��B
//�����ŁA**�ł��m���ŊȒP�ȕ��@**������Ă��܂��B
//����́A**�uWindows �� PARI/GP (gp.exe) ���C���X�g�[�����A
//Rust ����R�}���h�Ƃ��ČĂяo���v**�Ƃ������@�ł��B
//����Ȃ畡�G�Ȑݒ�Ȃ��ɁAPARI/GP �̔����G���W���𗘗p�ł��܂��B
//���̃v���O�����́A���� `gp` �R�}���h�����s���A�f���������� `factor(����)` �Ƃ����v�Z���s�킹�A
//���̌��ʁA�f�����ƌ��i��: `[3, 2; 5, 1]`�j�� Rust �ʼn�͂��ĕ\�����܂��B
//�P�D�������������l�����s���������e�L�X�g�E�t�@�C�����A�t�@�C�����J���_�C�A���O�Ŏw�肵�ēǂݍ��݂܂��B
//�Q�DPARI/GP �𗘗p���đf�����������܂��B
//�R�D���ʂ��A�ǂt�@�C�����̌��Ɂu_PrimeFactorization�v��t�����t�@�C�����ŁA
//// �ǂݍ��t�H���_�Ɠ����t�H���_�ɏ������݂܂��B
use regex::Regex;
use rfd::FileDialog;
use std::fs::File;
use std::io::{self, BufRead, BufReader, Write};
use std::path::Path;
use std::process::{Command, Stdio};
use std::time; // ���ԁiDuration, Instant�j���g�����߂̃��W���[��
// 1. �t�@�C�����J���_�C�A���O��\��
println!("�ǂݍ��ރe�L�X�g�t�@�C����I�����Ă�������...");
let file_path = match FileDialog ::new()
.add_filter("Text", &["txt"])
.set_directory(".") // �J�����g�f�B���N�g������J�n
.pick_file()
{
Some (path) => path,
None => {
println!("�t�@�C�����I������܂���ł����B�I�����܂��B");
return;
}
};
println!("�I�����ꂽ�t�@�C��: {:?}", file_path);
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// 2. �o�̓t�@�C�����̍쐬 (���̃t�@�C����_PrimeFactorization.txt)
let output_path = {
let parent = file_path.parent().unwrap_or(Path::new("."));
let file_stem = file_path.file_stem().unwrap().to_string_lossy();
let �V�t�@�C���� = format! ("{}_PrimeFactorization.txt", file_stem);
parent.join(�V�t�@�C����)
};
// �t�@�C���̃I�[�v���i�ǂݍ��ݗp�Ə������ݗp�j
let input_file = File::open(&file_path).expect("���̓t�@�C�����J���܂���");
let reader = BufReader::new(input_file);
let mut output_file = File::create(&output_path).expect("�o�̓t�@�C�����쐬�ł��܂���");
// �o�͉�͗p�̐��K�\�� (���O�ɃR���p�C��)
let re = Regex::new(r"(\d+),\s*(\d+)").unwrap();
println!("�������J�n���܂�...");
let mut count = 0;
// 3. �s���Ƃ̏���
for line in reader.lines() {
let line_content = line.unwrap_or_default();
let input_num = line_content.trim();
// ��s�␔�l�ȊO�̓X�L�b�v�i���̂܂o�͂��邩�A�������邩�I�ׂ܂��j
if input_num.is_empty() || !input_num.chars().all(|c| c.is_ascii_digit()) {
continue;
}
print!("����: {} ... ", input_num);
io::stdout().flush().unwrap();
// GP�����s���Č��ʕ�������擾
match run_gp_factorization(input_num, &re) {
Ok(result_str) => {
// ���ʂ��t�@�C���ɏ�������
writeln!(output_file, "{} = {}", input_num, result_str).unwrap();
println!("����");
}
Err(e) => {
println!("�G���[: {}", e);
writeln!(output_file, "{} = �G���[: {}", input_num, e).unwrap();
}
}
count += 1;
}
println!("--------------------------------------------------");
println!("���ׂĂ̏������������܂����B");
println!("��������: {} ��", count);
println!("�o�̓t�@�C��: {:?}", output_path);
println!("--------------------------------------------------");
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration�^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let ���� = ���v�b�� / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let �� = (���v�b�� % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let �b = ���v�b�� % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut �o�� = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if ���� > 0 {
�o��.push_str(&format! ("{}����", ����));
}
// �u���v��0���傫����Ε\���ɒlj�
if �� > 0 {
�o��.push_str(&format! ("{}��", ��));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if �b > 0 {
�o��.push_str(&format! ("{}�b", �b));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if �o��.is_empty() {
�o��.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println!("�o�ߎ���: {}", �o��);
// �E�B���h�E�������ɕ��Ȃ��悤�ɓ��͂�҂�
println!("\nEnter�L�[�������ďI�����Ă�������...");
let mut temp = String::new();
io::stdin().read_line(&mut temp).ok();
}
// �f���������̃��W�b�N���������܂���
// ���l����������A"�f���������̌��ʕ�����" ��Ԃ��܂�
// �R�}���h���C�������ŃX�^�b�N�T�C�Y���������Ă��܂�
// `gprc.txt` �Ɉˑ������A�v���O�������Łu���̂��炢�̃��������g���Ă���v�Ǝw�����܂��B
// GP �ɂ� `-s` �I�v�V����������A����ŃX�^�b�N�T�C�Y���w�肵�܂��B
// RSA-100�i���J���Í������̍l�Ď�3�l�iRivest�AShamir�AAdleman�j�̓������F100���j
// �̂悤�ȋ���Ȑ��������ꍇ�A�]�T�������� **256MB** ���x���蓖�Ă�ƈ��S�ł��B
fn run_gp_factorization(target_number: &str, re: &Regex) -> Result<String, String> {
// 1. gp �v���Z�X�𗧂��グ��
let mut child = Command::new("gp")
.arg("-q") // quiet mode (�o�i�[��\�����Ȃ�)
// .arg("-f") // fast mode �y�폜�z ���ꂪ����� gprc.txt ��ǂݍ��݂܂���I
.arg("-s").arg("256M") // �y�lj��z �X�^�b�N�T�C�Y���I��256MB�Ɏw��
.stdin(Stdio::piped())
.stdout(Stdio::piped())
.spawn()
.map_err(|e| format! ("�N�����s: {}", e))?;
// 2. gp �ɃR�}���h���M
{
let child_stdin = child.stdin.as_mut().ok_or("stdin�擾���s")?;
let command = format! ("print(factor({}));\n", target_number);
child_stdin
.write_all(command.as_bytes())
.map_err(|e| format! ("���M�G���[: {}", e))?;
}
// 3. ���ʎ�M
let output = child.wait_with_output().map_err(|e| format! ("�Ǎ����s: {}", e))?;
if !output.status.success() {
let err_msg = String::from_utf8_lossy(&output.stderr);
return Err(format! ("GP�v�Z�G���[: {}", err_msg));
}
let gp_output = String::from_utf8_lossy(&output.stdout);
// --- ��̓��W�b�N ---
let mut result_parts = Vec ::new();
for cap in re.captures_iter(&gp_output) {
let base = &cap[1];
let exp = &cap[2];
if exp == "1" {
result_parts.push(base.to_string());
} else {
result_parts.push(format! ("{}^{}", base, exp));
}
}
if result_parts.is_empty() {
// ���ʂ���̏ꍇ�i�ʏ킠�肦�܂��O�̂��ߐ��̌��ʂ�Ԃ��j
Ok(gp_output.trim().to_string())
} else {
Ok(result_parts.join(" * "))
}
}
rfd::FileDialog `)**:�T�D�f��������(msieve �g�p)
msieve �������ł��Bhttps://sourceforge.net/projects/msieve/files/msieve/Msieve%20v1.53/ https://stdkmd.net/nrr/msieve_ja.htm https://stdkmd.net/nrr/msieve_ja.htm#usage_options https://sekika.github.io/2015/11/08/msieve/ Claude �ɓ`������A���L�̃v���O���������Ă���܂����B�f��������(�t�@�C�����͂� msieve �g�p) ������܂��BRSA-100 = 1522605027922533360535618378132637429718068114961380688657908494580122963258952897654000350692006139 �� 3���� �őf���������ł��܂����I�I
[package]
name = "msieve_factorizer"
version = "0.1.0"
edition = "2021"
[dependencies]
num-bigint = "0.4"
num-traits = "0.2"
main.rs
// msieve_factorizer
// Claude �ɋ����Ă��炢�܂����B
use num_bigint::BigUint; //�q�[�v��ŔC�ӌ��̐�����ێ����邽�߁A
//���_��͌����̏��������܂���i���ۂɂ� msieve ���g�̏���Ɉˑ����܂��j
use num_traits::One;
use std::io::{self, Write};
use std::process::Command;
use std::str::FromStr;
use std::time; // ���ԁiDuration, Instant�j���g�����߂̃��W���[��
use std::fs::{self};
use std::path::{Path}; //�t�@�C����f�B���N�g���̃p�X����������悤��
// ����������������������������������������������������������������������
// main
// ����������������������������������������������������������������������
fn main() {
println!("============================================================");
println!(" msieve �f���������c�[�� (Rust��) ��100���ȏ�Ή�");
println!("============================================================");
println!("�I������ɂ� 'q' ����͂��Ă��������B");
println!();
loop {
print!("�� �f�����������鐔����͂��Ă�������(q �ŏI��): ");
io::stdout().flush().unwrap();
let mut input = String::new();
io::stdin().read_line(&mut input).unwrap();
let input = input.trim();
// �I��
if input.eq_ignore_ascii_case("q") {
println!("�v���O�������I�����܂��B");
break;
}
// �����
if input.is_empty() {
println!("���l����͂��Ă��������B\n");
continue;
}
// �o���f�[�V����
let n = match parse_input (input) {
Ok(v) => v,
Err(msg) => {
println!("{} ('q' �ŏI��)\n", msg);
continue;
}
};
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// �����\���i�傫�Ȑ��ɂ͌������\���j
let digits = input.len();
if digits > 15 {
println!(
"({} ���̐�) msieve �őf��������... ���炭���҂����������B",
digits
);
} else {
println!("msieve �őf��������... ���炭���҂����������B");
}
match �f�������� (input) {
Ok(factors) => {
// ��������
let short_expr = format_factors_short (&n, &factors);
println!("��������: {}", short_expr);
println!("");
// ���؎�
let full_expr = format_factors_full (&n, &factors);
println!("���؎� : {}", full_expr);
// ����
if verify_factors (&n, &factors) {
println!("���،���: OK ��");
} else {
println!("���،���: NG �~ (�ς����̐��ƈ�v���܂���)");
}
}
Err(e) => {
eprintln!("�G���[: {}", e);
}
}
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration�^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let ���� = ���v�b�� / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let �� = (���v�b�� % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let �b = ���v�b�� % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^ �j
let mut �o�� = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if ���� > 0 {
�o��.push_str(&format!("{}����", ����));
}
// �u���v��0���傫����Ε\���ɒlj�
if �� > 0 {
�o��.push_str(&format!("{}��", ��));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if �b > 0 {
�o��.push_str(&format!("{}�b", �b));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if �o��.is_empty() {
�o��.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println!("�o�ߎ���: {}", �o��);
println!();
// msieve.dat ��폜�i���̏����̂��߁j
delete_msieve_dat ();
}
}
// ����������������������������������������������������������������������
// msieve ���Ăяo���đf��������
// msieve153.exe ���T�u�v���Z�X�ŌĂяo���Astdout/stderr ���擾
// ����������������������������������������������������������������������
fn �f�������� (n_str: &str) -> Result<Vec <(BigUint, u32)>, String> {
let output = Command::new("msieve153.exe")
.args(["-e", "-v", n_str])
// -e�F�f���������ɑȉ~�Ȑ��@(ECM)��p����B-v�F����(���O)����ʂɕ\������
.output()
.map_err(|e| format!("msieve153.exe �̎��s�Ɏ��s���܂���: {}", e))?;
let stdout = String::from_utf8_lossy(&output.stdout).to_string();
let stderr = String::from_utf8_lossy(&output.stderr).to_string();
// msieve �� stdout / stderr �̗����ɏ����o���ꍇ������
let combined = format!("{}\n{}", stdout, stderr);
// �G���[������`�F�b�N�i"error" ���܂ލs�̂݊m�F�j
let has_error = combined
.lines()
.any(|l| l.to_lowercase().contains("error"));
if has_error {
return Err(format!("msieve �G���[:\n{}", combined));
}
let factors = parse_factors (&combined);
if factors.is_empty() {
Err(format!(
"�f�������擾�ł��܂���ł����B\nmsieve �o��:\n{}",
combined
))
} else {
Ok(factors)
}
}
// ����������������������������������������������������������������������
// msieve �o�͂̃p�[�X
// msieve �͑f�������ȉ��̌`���ŏo�͂��܂�:
// p1: 3
// p3: 101
// p10: 1234567891 �� �������傫���ꍇ�� BigUint �Ŏ��
// p3: 101 �`���̍s�𐳋K�\���Ȃ��Ńp�[�X�� (�f����, �w��) �ɐ���
// ����������������������������������������������������������������������
fn parse_factors (output: &str) -> Vec <(BigUint, u32)> {
let mut factors: Vec <BigUint> = Vec ::new();
for line in output.lines() {
let trimmed = line.trim();
// "p" �Ŏn�܂� ":" ���܂ލs���f�����s
if trimmed.starts_with('p') && trimmed.contains(':') {
let parts: Vec <&str> = trimmed.splitn(2, ':').collect();
if parts.len() == 2 {
let num_str = parts[1].trim();
if let Ok(n) = BigUint::from_str(num_str) {
if n > BigUint::one() {
factors.push(n);
}
}
}
}
}
// �����\�[�g��A�����f�������܂Ƃ߂� (�f����, �w��) �̃y�A�ɂ���
factors.sort();
let mut result: Vec <(BigUint, u32)> = Vec ::new();
for f in factors {
if let Some (last) = result.last_mut() {
if last.0 == f {
last.1 += 1;
continue;
}
}
result.push((f, 1));
}
result
}
// ����������������������������������������������������������������������
// �\���p�t�H�[�}�b�g
// ����������������������������������������������������������������������
/// �������ʍs: �w��1�͏ȗ�
/// ��) 1234567890123456789 = 3^2 * 101 * 3541 * �c
/// �w��1�͏ȗ����� �������� �p�̕������
/// &BigUint, ... �Q�Ɠn���ŃR�s�[�R�X�g�팸
fn format_factors_short (n: &BigUint, factors: &[(BigUint, u32)]) -> String {
let parts: Vec <String> = factors
.iter()
.map(|(base, exp)| {
if *exp == 1 {
format!("{}", base)
} else {
format!("{}^{}", base, exp)
}
})
.collect();
format!("{} = {}", n, parts.join(" * "))
}
/// ���؎��s: �S�Ă̎w����\��
/// ��) 3^2 * 101^1 * �c = 1234567890123456789
/// �S�w����\������ ���؎� �p�̕������
fn format_factors_full (n: &BigUint, factors: &[(BigUint, u32)]) -> String {
let parts: Vec <String> = factors
.iter()
.map(|(base, exp)| format!("{}^{}", base, exp))
.collect();
format!("{} = {}", parts.join(" * "), n)
}
// ����������������������������������������������������������������������
// ����: �f�����̐� == ���̐�
// ����������������������������������������������������������������������
fn verify_factors (n: &BigUint, factors: &[(BigUint, u32)]) -> bool {
let product = factors
.iter()
.fold(BigUint::one(), |acc, (base, exp)| acc * base.pow(*exp));
&product == n
}
// ����������������������������������������������������������������������
// ���͕�����̃o���f�[�V����
// ���͕������̐��� (>= 2) ���ǂ����m�F
// ����������������������������������������������������������������������
fn parse_input (s: &str) -> Result<BigUint, &'static str> {
// �����t�����͎͂t���Ȃ��imsieve �ɓn������������̂܂g�����߁j
if s.starts_with('+') || s.starts_with('-') {
return Err("�����Ȃ��̐��̐�������͂��Ă��������B");
}
match BigUint::from_str(s) {
Ok(n) if n >= BigUint::from(2u32) => Ok(n),
Ok(_) => Err("2�ȏ�̐�������͂��Ă��������B"),
Err(_) => Err("�L���Ȑ�������͂��Ă��������B"),
}
}
// ����������������������������������������
// msieve.dat �폜
// msieve.dat �́A�����ߒ����L�^���钆�ԃt�@�C���ŁA�傫�ȃT�C�Y�ł��B
// msieve.dat �́A���O�ɒ��f�E���������������ĊJ�ł���悤�ɂ��邽�߂̂��̂ł��B
// ����������������������������������������
fn delete_msieve_dat () {
let dat_path = Path::new("msieve.dat");
if dat_path.exists() {
if let Err(e) = fs::remove_file (dat_path) {
eprintln!("�x��: msieve.dat �̍폜�Ɏ��s���܂���: {}", e);
} else {
println!("msieve.dat ���폜���܂����B");
}
println!();
}
}
�U�D�f��������(�t�@�C�����͂� msieve �g�p)
�f��������(msieve �g�p) �ŁA���������ł��邱�Ƃ����������̂ŁA�Ώې��l���t�@�C������ǂݍ��މ��L�̎d�l�� Claude �ɓ`���܂����Bsample_input.zip �f��������(msieve �g�p) �̃R�[�h���A�t�@�C���p�ɏC���������̂Ŏ��s���܂��BClaude ������R�[�h�ł��B
[package]
name = "msieve_factor_File"
version = "0.1.0"
edition = "2021"
[dependencies]
num-bigint = "0.4"
num-traits = "0.2"
rfd = "0.15"
// msieve_factor_File
// Claude �ɋ����Ă��炢�܂����B
use num_bigint::BigUint;
use num_traits::One;
use rfd::FileDialog;
use std::fs::{self, File};
use std::io::{BufRead, BufReader, Write};
use std::path::{Path, PathBuf }; //�t�@�C����f�B���N�g���̃p�X����������悤��
//�p�X�ƃt�@�C���V�X�e���̑���
use std::process::Command;
use std::str::FromStr;
use std::time; // ���ԁiDuration, Instant�j���g�����߂̃��W���[��
// ����������������������������������������
// main
// ����������������������������������������
fn main() {
println!("============================================================");
println!(" msieve �o�b�`�f���������c�[�� (Rust��)");
println!("============================================================");
println!("�f�����������鐔�l���L�ڂ��ꂽ�e�L�X�g�t�@�C����I�����Ă��������B");
println!();
// �t�@�C���_�C�A���O
let �t�@�C���p�X = FileDialog::new()
.add_filter("�e�L�X�g�t�@�C��", &["txt"])
.add_filter("���ׂẴt�@�C��", &["*"])
.set_title("�f�����������鐔�l���܂ރt�@�C����I��")
.pick_file();
let ���̓p�X = match �t�@�C���p�X {
Some (path) => path,
// ����`path`��**�ϐ���**�ł��B
// `FileDialog`���Ԃ�`Option<PathBuf >`�^�̒l�����Ď��o�������̂ł��B
// `Some (path)`�Ń}�b�`����ƁA`path`�ɂ�`PathBuf `�^�̒l������܂�
// `PathBuf `��**���L�������p�X**�i�q�[�v�Ɋm�ۂ��ꂽ�A�ύX�\�ȃp�X���j
None => {
println!("�t�@�C�����I������܂���ł����B�v���O�������I�����܂��B");
return;
}
};
// ���̎����i�v���J�n�n�_�j���擾
let �J�n���� = time::Instant::now();
// �o�b�`�������s
match process_batch_file (&���̓p�X) {
Ok(_) => {
println!("\n���ׂĂ̏���������Ɋ������܂����B");
}
Err(e) => {
eprintln!("\n�G���[���������܂���: {}", e);
}
}
// �ŏ��̎�������̌o�ߎ��Ԃ��擾�iDuration�^�j
let �o�ߎ��� = �J�n����.elapsed();
// �o�ߎ��Ԃ́u���v�b���v���擾
let ���v�b�� = �o�ߎ���.as_secs();
// ���v�b������u���ԁE���E�b�v���Z���Ōv�Z����
let ���� = ���v�b�� / 3600; // 3600�b�Ŋ���Ɓu���ԁv
let �� = (���v�b�� % 3600) / 60; // ���Ԃ̗]���60�Ŋ���Ɓu���v
let �b = ���v�b�� % 60; // ����ɂ��̗]�肪�u�b�v
// �\���p�̕���������i�ς�String�^�j
let mut �o�� = String::new();
// �u���ԁv��0���傫����Ε\���ɒlj�
if ���� > 0 {
�o��.push_str(&format!("{}����", ����));
}
// �u���v��0���傫����Ε\���ɒlj�
if �� > 0 {
�o��.push_str(&format!("{}��", ��));
}
// �u�b�v��0���傫����Ε\���ɒlj�
if �b > 0 {
�o��.push_str(&format!("{}�b", �b));
}
// �����S��0�������ꍇ�i1�b�����j�́u0�b�v�ƕ\������Ȃǂ̑�
if �o��.is_empty() {
�o��.push_str("0�b");
}
// �ŏI�I�Ȍ��ʂ�\��
println!("�o�ߎ���: {}", �o��);
println!("\nEnter�L�[�������ďI�����Ă�������...");
let mut dummy = String::new();
std::io::stdin().read_line(&mut dummy).ok();
}
// ����������������������������������������
// �o�b�`����: �t�@�C������ǂݍ���őf�����������Č��ʂ��t�@�C���ɏ�������
// ����������������������������������������
fn process_batch_file (���̓p�X: &Path ) -> Result<(), String> {
// ���̓t�@�C�����J��
// ����`&Path`��**�^��**�ł��B��̓I�ɂ́F
// `Path`��**�p�X��\���^**�i�W�����C�u������`std::path::Path`�j
// `&Path`��**Path�ւ̎Q��**�i�ؗp�j
let file = File::open(���̓p�X)
.map_err(|e| format!("�t�@�C�� '{}' ���J���܂���ł���: {}", ���̓p�X.display(), e))?;
let reader = BufReader::new(file);
// �o�̓t�@�C������
let �o�̓p�X = �o�̓p�X���� (���̓p�X);
let mut �o�̓t�@�C�� = File::create(&�o�̓p�X)
.map_err(|e| format!("�o�̓t�@�C�� '{}' ���쐬�ł��܂���ł���: {}", �o�̓p�X.display(), e))?;
println!("���̓t�@�C��: {}", ���̓p�X.display());
println!("�o�̓t�@�C��: {}", �o�̓p�X.display());
println!();
// �w�b�_�[��������
writeln!(�o�̓t�@�C��, "============================================================")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, " msieve �f�������� �o�b�`��������")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "============================================================")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "���̓t�@�C��: {}", ���̓p�X.display())
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "")
.map_err(|e| format!("�������݃G���[: {}", e))?;
let mut line_number = 0;
let mut success_count = 0;
let mut error_count = 0;
// �e�s������
for line_result in reader.lines() {
line_number += 1;
let line = line_result
.map_err(|e| format!("�s{}�̓ǂݍ��݃G���[: {}", line_number, e))?;
let input = line.trim();
// ��s��R�����g�s���X�L�b�v
if input.is_empty() || input.starts_with('#') || input.starts_with("//") {
continue;
}
println!("������������������������������������������������������");
println!("[�s {}] ������: {}", line_number, input);
writeln!(�o�̓t�@�C��, "������������������������������������������������������")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "[�s {}] ����: {}", line_number, input)
.map_err(|e| format!("�������݃G���[: {}", e))?;
// �o���f�[�V����
let n = match parse_input (input) {
Ok(v) => v,
Err(msg) => {
println!("�G���[: {}", msg);
writeln!(�o�̓t�@�C��, "�G���[: {}", msg)
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "")
.map_err(|e| format!("�������݃G���[: {}", e))?;
error_count += 1;
continue;
}
};
// �����\��
let digits = input.len();
println!("({} ��) msieve �őf��������...", digits);
// �f�����������s
match �f�������� (input) {
Ok(factors) => {
let short_expr = format_factors_short (&n, &factors);
let full_expr = format_factors_full (&n, &factors);
let verification_ok = verify_factors (&n, &factors);
println!("��������: {}", short_expr);
println!("���؎� : {}", full_expr);
if verification_ok {
println!("���،���: OK �Z");
} else {
println!("���،���: NG �~");
}
writeln!(�o�̓t�@�C��, "��������: {}", short_expr)
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "���؎� : {}", full_expr)
.map_err(|e| format!("�������݃G���[: {}", e))?;
if verification_ok {
writeln!(�o�̓t�@�C��, "���،���: OK ?")
.map_err(|e| format!("�������݃G���[: {}", e))?;
} else {
writeln!(�o�̓t�@�C��, "���،���: NG ?")
.map_err(|e| format!("�������݃G���[: {}", e))?;
}
writeln!(�o�̓t�@�C��, "")
.map_err(|e| format!("�������݃G���[: {}", e))?;
success_count += 1;
// msieve.dat ��폜�i���̏����̂��߁j
delete_msieve_dat ();
}
Err(e) => {
println!("�G���[: {}", e);
writeln!(�o�̓t�@�C��, "�G���[: {}", e)
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "")
.map_err(|e| format!("�������݃G���[: {}", e))?;
error_count += 1;
// �G���[���� msieve.dat ���폜
delete_msieve_dat ();
}
}
println!();
}
// �T�}���[
println!("============================================================");
println!(" ��������");
println!("============================================================");
println!("����: {} ��", success_count);
println!("���s: {} ��", error_count);
println!("�o�̓t�@�C��: {}", �o�̓p�X.display());
writeln!(�o�̓t�@�C��, "============================================================")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, " ��������")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "============================================================")
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "����: {} ��", success_count)
.map_err(|e| format!("�������݃G���[: {}", e))?;
writeln!(�o�̓t�@�C��, "���s: {} ��", error_count)
.map_err(|e| format!("�������݃G���[: {}", e))?;
Ok(())
}
// ����������������������������������������
// msieve ���Ăяo���đf��������
// msieve153.exe ���T�u�v���Z�X�ŌĂяo���Astdout/stderr ���擾
// ����������������������������������������
fn �f��������(n_str: &str) -> Result<Vec <(BigUint, u32)>, String> {
let output = Command::new("msieve153.exe")
.args(["-e", "-v", n_str])
// -e�F�f���������ɑȉ~�Ȑ��@(ECM)��p����B-v�F����(���O)����ʂɕ\������
.output()
.map_err(|e| format!("msieve153.exe �̎��s�Ɏ��s���܂���: {}", e))?;
let stdout = String::from_utf8_lossy(&output.stdout).to_string();
let stderr = String::from_utf8_lossy(&output.stderr).to_string();
// msieve �� stdout / stderr �̗����ɏ����o���ꍇ������
let combined = format!("{}\n{}", stdout, stderr);
// �G���[������`�F�b�N�i"error" ���܂ލs�̂݊m�F�j
let has_error = combined
.lines()
.any(|l| l.to_lowercase().contains("error"));
if has_error {
return Err(format!("msieve �G���[:\n{}", combined));
}
let factors = parse_factors(&combined);
if factors.is_empty() {
Err(format!(
"�f�������擾�ł��܂���ł����B\nmsieve �o��:\n{}",
combined
))
} else {
Ok(factors)
}
}
// ����������������������������������������
// msieve �o�͂̃p�[�X
// msieve �͑f�������ȉ��̌`���ŏo�͂��܂�:
// p1: 3
// p3: 101
// p10: 1234567891 �� �������傫���ꍇ�� BigUint �Ŏ��
// p3: 101 �`���̍s�𐳋K�\���Ȃ��Ńp�[�X�� (�f����, �w��) �ɐ���
// ����������������������������������������
fn parse_factors(output: &str) -> Vec <(BigUint, u32)> {
let mut factors: Vec <BigUint> = Vec ::new();
for line in output.lines() {
let trimmed = line.trim();
// "p" �Ŏn�܂� ":" ���܂ލs���f�����s
if trimmed.starts_with('p') && trimmed.contains(':') {
let parts: Vec <&str> = trimmed.splitn(2, ':').collect();
if parts.len() == 2 {
let num_str = parts[1].trim();
if let Ok(n) = BigUint::from_str(num_str) {
if n > BigUint::one() {
factors.push(n);
}
}
}
}
}
// �����\�[�g��A�����f�������܂Ƃ߂� (�f����, �w��) �̃y�A�ɂ���
factors.sort();
let mut result: Vec <(BigUint, u32)> = Vec ::new();
for f in factors {
if let Some (last) = result.last_mut() {
if last.0 == f {
last.1 += 1;
continue;
}
}
result.push((f, 1));
}
result
}
// ����������������������������������������
// �\���p�t�H�[�}�b�g
// ����������������������������������������
/// �������ʍs: �w��1�͏ȗ�
/// ��) 1234567890123456789 = 3^2 * 101 * 3541 * �c
/// �w��1�͏ȗ����� �������� �p�̕������
/// &BigUint, ... �Q�Ɠn���ŃR�s�[�R�X�g�팸
fn format_factors_short(n: &BigUint, factors: &[(BigUint, u32)]) -> String {
let parts: Vec <String> = factors
.iter()
.map(|(base, exp)| {
if *exp == 1 {
format!("{}", base)
} else {
format!("{}^{}", base, exp)
}
})
.collect();
format!("{} = {}", n, parts.join(" * "))
}
/// ���؎��s: �S�Ă̎w����\��
/// ��) 3^2 * 101^1 * �c = 1234567890123456789
/// �S�w����\������ ���؎� �p�̕������
fn format_factors_full(n: &BigUint, factors: &[(BigUint, u32)]) -> String {
let parts: Vec <String> = factors
.iter()
.map(|(base, exp)| format!("{}^{}", base, exp))
.collect();
format!("{} = {}", parts.join(" * "), n)
}
// ����������������������������������������
// ����: �f�����̐� == ���̐�
// ����������������������������������������
fn verify_factors(n: &BigUint, factors: &[(BigUint, u32)]) -> bool {
let product = factors
.iter()
.fold(BigUint::one(), |acc, (base, exp)| acc * base.pow(*exp));
&product == n
}
// ����������������������������������������
// ���͕�����̃o���f�[�V����
// ���͕������̐��� (>= 2) ���ǂ����m�F
// ����������������������������������������
fn parse_input(s: &str) -> Result<BigUint, String> {
// �����t�����͎͂t���Ȃ��imsieve �ɓn������������̂܂g�����߁j
if s.starts_with('+') || s.starts_with('-') {
return Err("�����Ȃ��̐��̐�������͂��Ă��������B".to_string());
}
match BigUint::from_str(s) {
Ok(n) if n >= BigUint::from(2u32) => Ok(n),
Ok(_) => Err("2�ȏ�̐�������͂��Ă��������B".to_string()),
Err(_) => Err("�L���Ȑ�������͂��Ă��������B".to_string()),
}
}
// ����������������������������������������
// �o�̓t�@�C�����̐���: input.txt �� input_factor.txt
// ����������������������������������������
fn �o�̓p�X���� (���̓p�X: &Path ) -> PathBuf {
let parent = ���̓p�X.parent().unwrap_or(Path::new("."));
let stem = ���̓p�X.file_stem().unwrap_or_default();
let ext = ���̓p�X.extension().unwrap_or_default();
let �V�t�@�C���p�X = if ext.is_empty() {
format!("{}_factor", stem.to_string_lossy())
} else {
format!("{}_{}.{}", stem.to_string_lossy(), "factor", ext.to_string_lossy())
};
parent.join(�V�t�@�C���p�X)
}
// ����������������������������������������
// msieve.dat �폜
// msieve.dat �́A�����ߒ����L�^���钆�ԃt�@�C���ŁA�傫�ȃT�C�Y�ł��B
// msieve.dat �́A���O�ɒ��f�E���������������ĊJ�ł���悤�ɂ��邽�߂̂��̂ł��B
// ����������������������������������������
fn delete_msieve_dat() {
let dat_path = Path::new("msieve.dat");
if dat_path.exists() {
if let Err(e) = fs::remove_file(dat_path) {
eprintln!("�x��: msieve.dat �̍폜�Ɏ��s���܂���: {}", e);
} else {
println!("msieve.dat ���폜���܂����B");
}
}
}
## PathBuf �� &Path �̊W
�^ ���� �Ⴆ `PathBuf` ���L�������p�X�i�ύX�\�j `String`�̂悤�Ȃ��� `&Path` �p�X�ւ̎Q�Ɓi�ǂݎ���p�j `&str`�̂悤�Ȃ���
// PathBuf �� &Path �ւ̕ϊ��͎����I�ɍs����
let owned: PathBuf = PathBuf::from("C:\\Users\\file.txt");
let borrowed: &Path = &owned; // �Q�Ƃ����
// ���ɓn���Ƃ�
process_batch_file(&owned); // PathBuf �̎Q�Ƃ�n��
let input_path = match file_path {
Some (path) => path, // PathBuf ���擾�i���L�����ړ��j
None => { return; }
};
// PathBuf �����L���Ă��邪�A���ɂ͎Q�Ƃœn��
process_batch_file(&input_path); // &PathBuf �͎����I�� &Path �ɂȂ�
// ^^^^^^^^^^^^^ �ؗp�L�� & �ŎQ�Ƃ�n��
�@Option�^�ɗL���Ȓl�𑩔�����Ƃ��� Some ���g���܂��Bhttps://doc.rust-lang.org/rust-by-example/ja/std/option.html
fn main() {
// PathBuf ���擾�i���L������j
let input_path: PathBuf = PathBuf::from("input.txt");
// ���ɎQ�Ƃœn��
process_batch_file(&input_path); // ���L���� main �Ɏc��
// �܂� input_path ���g����I
println!("���������t�@�C��: {}", input_path.display());
}
fn process_batch_file(input_path: &Path) -> Result<(), String> {
// �� &Path �Ŏ�� = �ؗp���� = �ǂݎ���p
// �p�X�̏���ǂނ����i�ύX�͂��Ȃ��j
println!("�t�@�C����: {:?}", input_path.file_name());
println!("�g���q: {:?}", input_path.extension());
Ok(())
}
�R�[�h �Ӗ� `path` �ϐ����i���g��`PathBuf`�^�̒l�j `&Path` �^���iPath�ւ̎Q�ƌ^�j `&input_path` `input_path`�̎Q�Ƃ���鑀��
https://rust-tech.nkhn37.net/rust-string-str-basic/ https://note.com/marupeke296/n/n9b69cc5b45d4 Rust �p��W https://panda-program.com/posts/book-understanding-rust 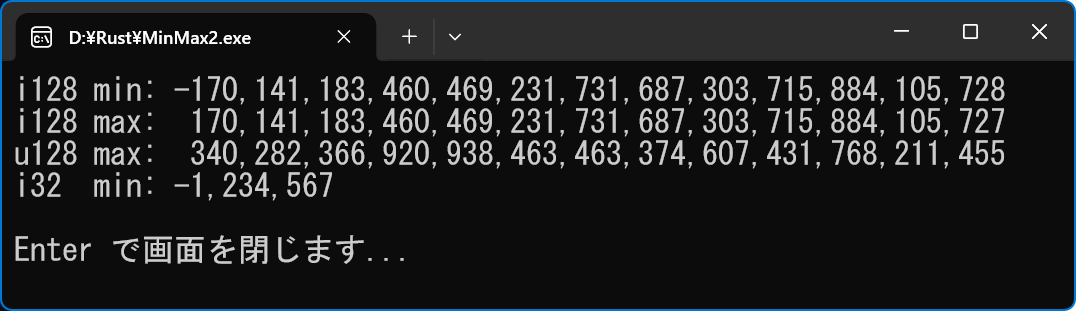 �@�����^�̍ŏ��l�A�ő�l��\�����܂��B
�@�����^�̍ŏ��l�A�ő�l��\�����܂��B
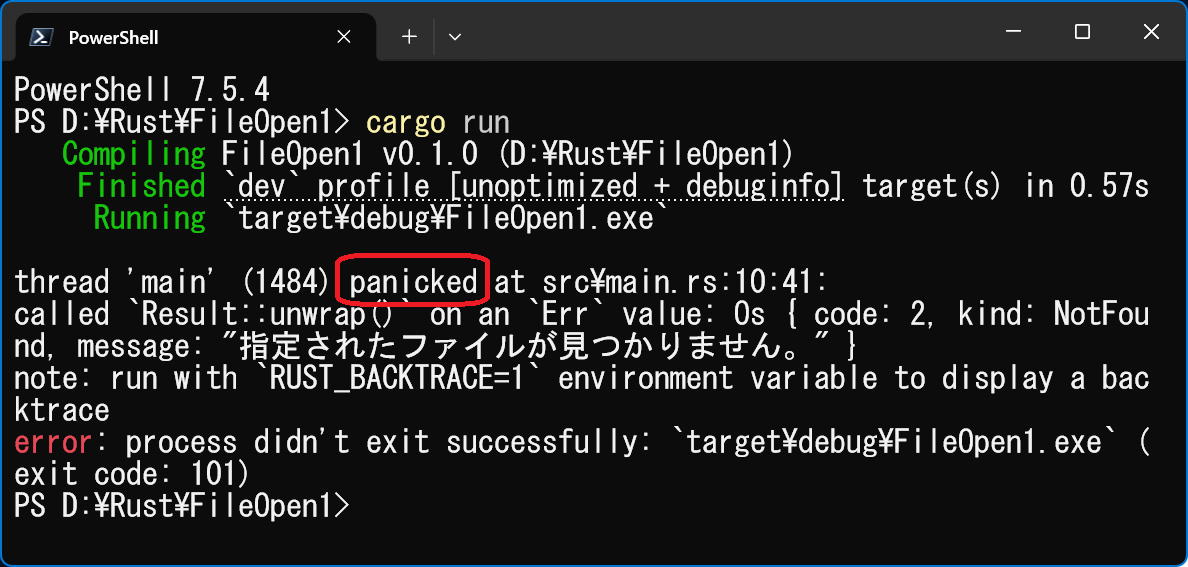 �@### 1. `fn main() {` �i��{�̌`�j
�@### 1. `fn main() {` �i��{�̌`�j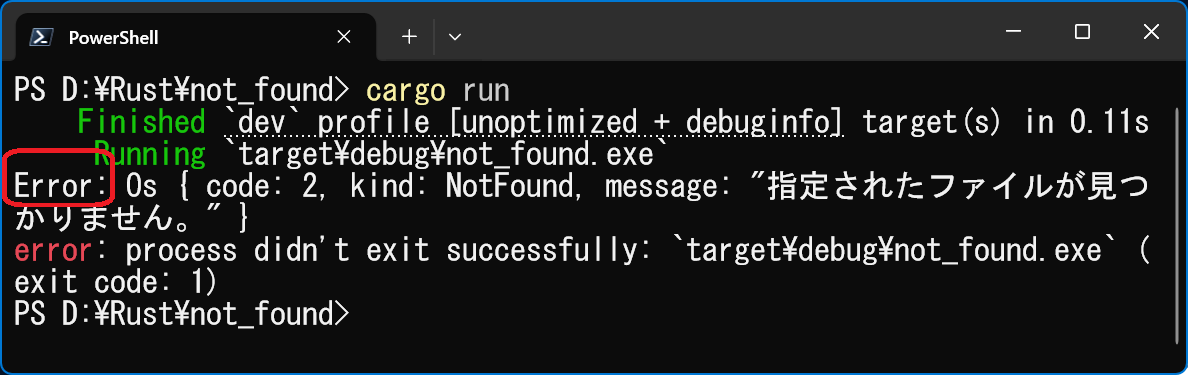 2. **`fn main() -> io::Result<()> {` ���g���Ƃ�**
2. **`fn main() -> io::Result<()> {` ���g���Ƃ�**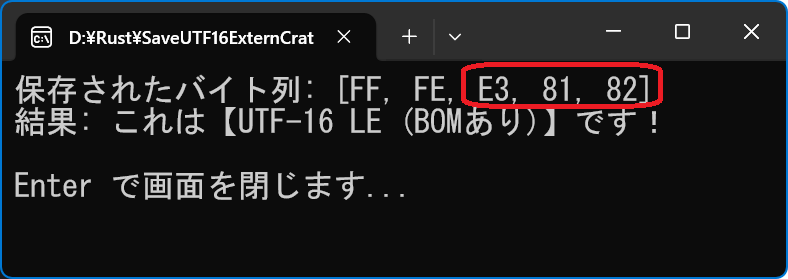 �R�D�ۑ������t�@�C���̕����R�[�h���m�F����
�R�D�ۑ������t�@�C���̕����R�[�h���m�F����
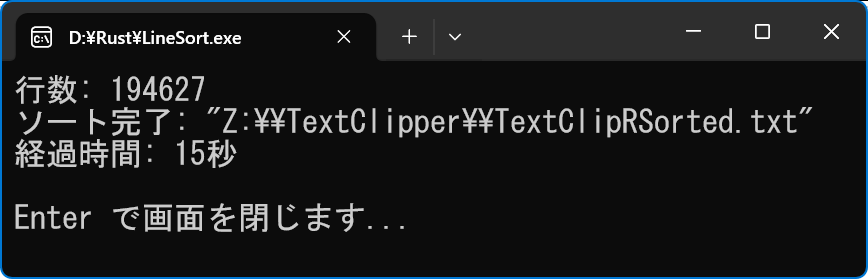

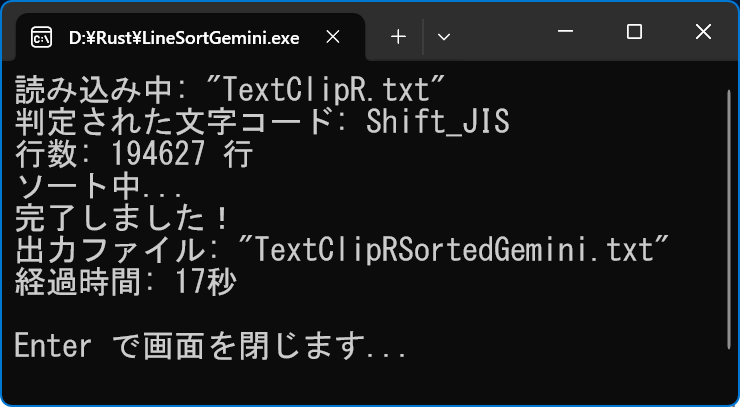
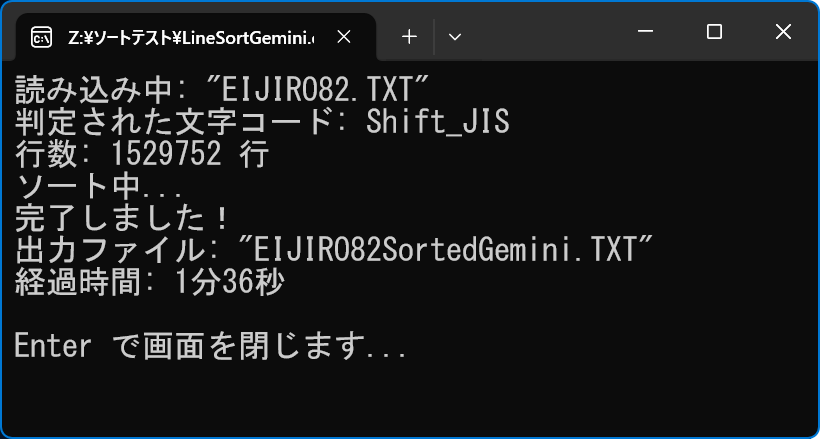
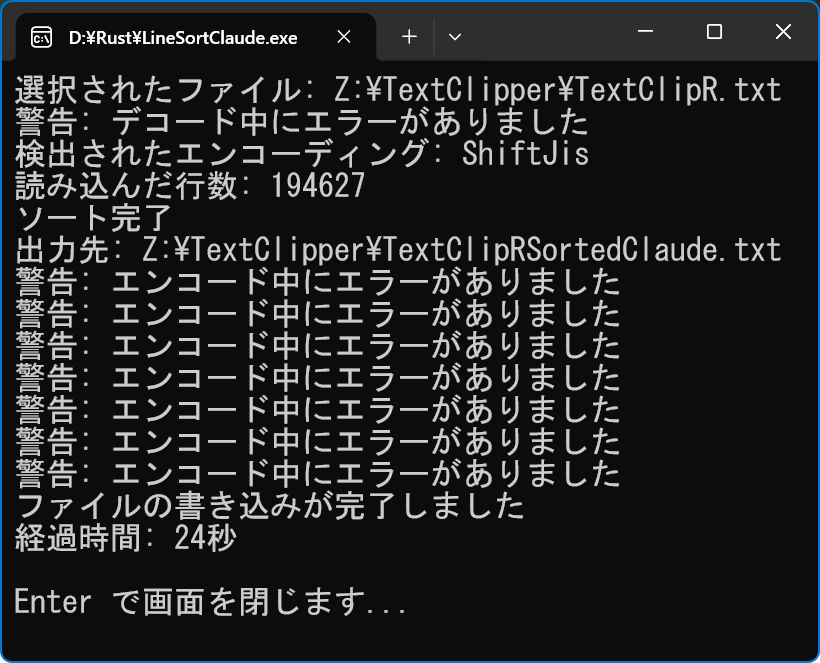

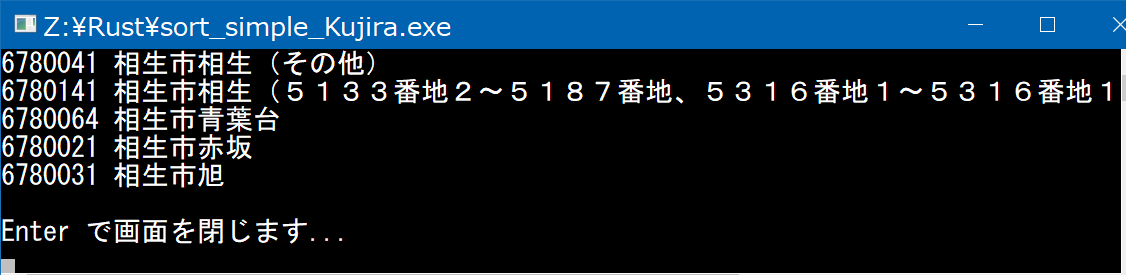 �@�N�W����s�����ARust�ŗL���A���S���Y���ɒ����Ƃ����A�ڋL����������Ă��܂��B
�@�N�W����s�����ARust�ŗL���A���S���Y���ɒ����Ƃ����A�ڋL����������Ă��܂��B factorization3JP.rs �����C�y Rust �v���O���~���O������̃R�[�h �Ɏ�����������̂ł�
factorization3JP.rs �����C�y Rust �v���O���~���O������̃R�[�h �Ɏ�����������̂ł�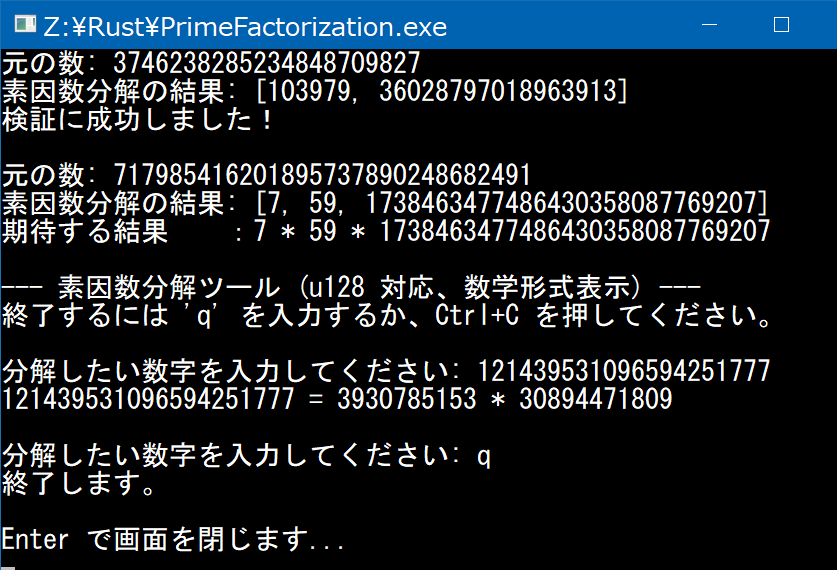 �@Rust �ɂ͍ő�128�r�b�g�����܂Ŏg����f�����������C�u���� prime_factorization ������܂��B
�@Rust �ɂ͍ő�128�r�b�g�����܂Ŏg����f�����������C�u���� prime_factorization ������܂��B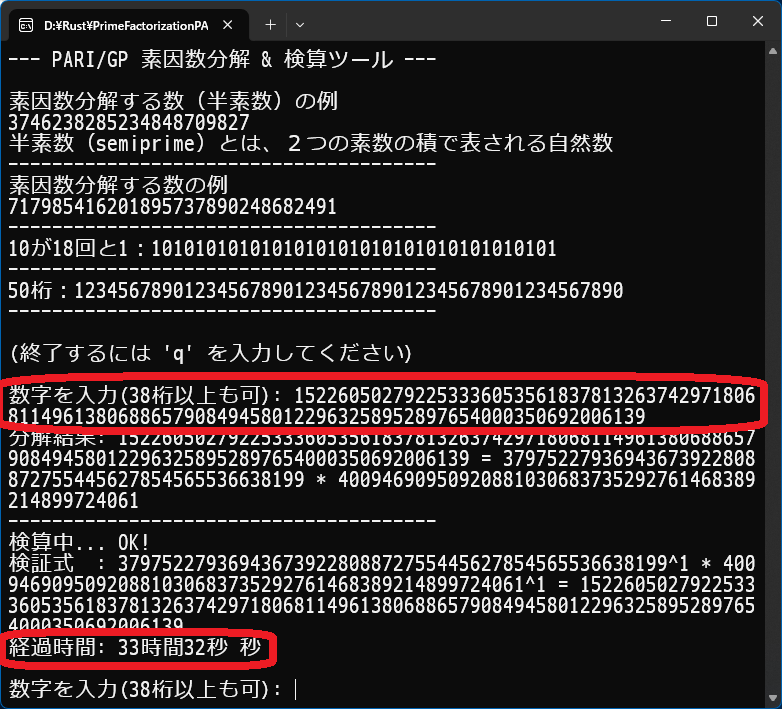 �@Rust ���� PARI/GP (gp.exe) �𗘗p���đf�����������܂��B
�@Rust ���� PARI/GP (gp.exe) �𗘗p���đf�����������܂��B �@PARI/GP (gp.exe) �𗘗p����ƁA�傫�ȑf�����|�����킹�������̑������ł��A�����őf���������ł������Ƃ�������܂����B
�@PARI/GP (gp.exe) �𗘗p����ƁA�傫�ȑf�����|�����킹�������̑������ł��A�����őf���������ł������Ƃ�������܂����B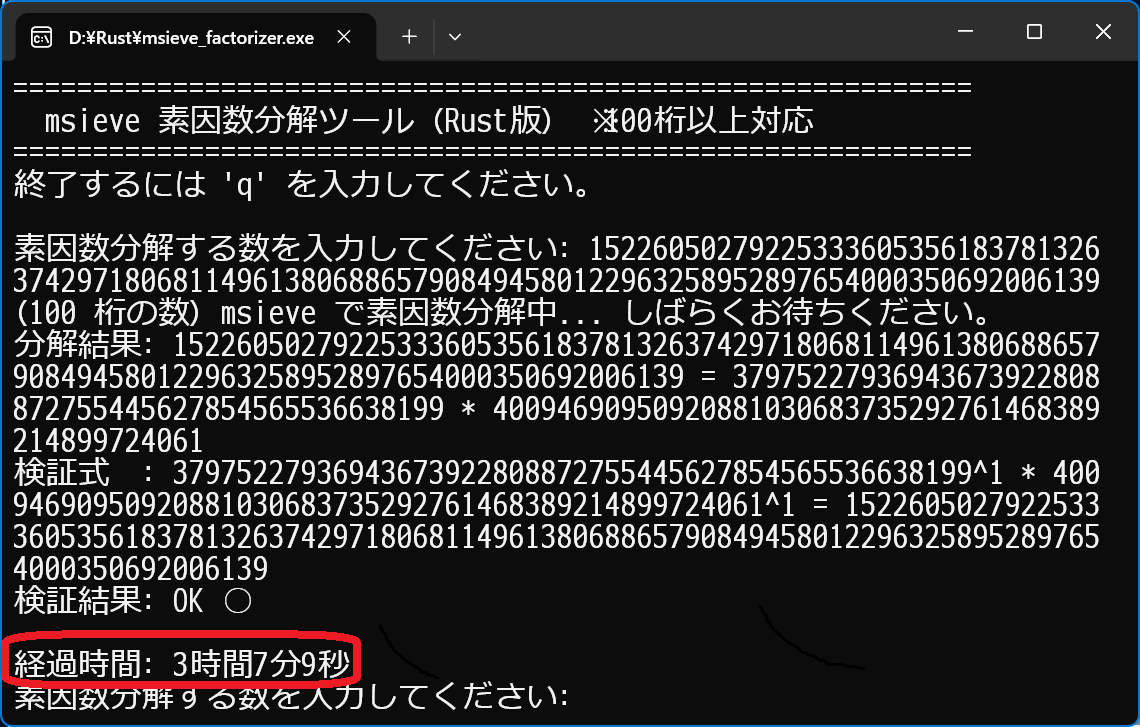 �@�f���������v���O�����Ƃ����Amsieve �������ł��B
�@�f���������v���O�����Ƃ����Amsieve �������ł��B �@�f��������(msieve �g�p)�ŁA���������ł��邱�Ƃ����������̂ŁA�Ώې��l���t�@�C������ǂݍ��މ��L�̎d�l�� Claude �ɓ`���܂����B
�@�f��������(msieve �g�p)�ŁA���������ł��邱�Ƃ����������̂ŁA�Ώې��l���t�@�C������ǂݍ��މ��L�̎d�l�� Claude �ɓ`���܂����B