Excel VBA ���i�\�W�J

���i�\�Ƃ�
�@���i�\(BOM:bill of materials) �́A�����Ƃ̊�{���̊�{�́A�}�X�^�[�E�f�[�^�ł��B
�@���i�\�́A���p�����ʂɂ���āA6�̓W�J���@���g���܂��B
| �P�D�V���O���E���x���W�J | �Q�D�V���O���E���x���t�W�J |
| �R�D�}���`�E���x���W�J | �S�D�}���`�E���x���t�W�J |
| �T�D�W��W�J | �U�D�W��t�W�J |
�@�R���s���[�^���f�[�^�x�[�X�̒��ɂ́A�V���O���E���x���W�J �̌`���Ńf�[�^���Ǘ����āA�d����h���ł��܂��B
�@�����ł́A�V���O���E���x���W�J�̃f�[�^���A�}���`�E���x���W�J�ƁA�W��W�J���� Excel �}�N���A
����сA�}���`�E���x���W�J�̃f�[�^����A�V���O���E���x���W�J�̃f�[�^�𒊏o���� �}�N�����A�Љ�܂��B
[���쌠]
�@���̃y�[�W�́A�I���W�i���̃A�C�f�A�Ń}�N�����쐬���Ă���A�n�Ӑ^���A���쌠��ۗL���܂��B
�@�N���G�C�e�B�u�E�R�����Y�́u�\��-��c��-�p��  Attribution-NonCommercial-ShareAlike�v�ɏ������āA���J���܂��B
Attribution-NonCommercial-ShareAlike�v�ɏ������āA���J���܂��B
���i�\�̃��[���x���E�R�[�h�ݒ�
�@���i�\�ł́A����i���A�����̊K�w�ɏo������\�����L��܂��B���̂Ƃ��A���̐e�i�ڂ��g����A�����Ƃ����̃��x���̃��x���ԍ����A���[���x���R�[�h(LLC)�ƌĂт܂��B
�@�@�@�@�@�@�@�`�����x���P
�@�@�@�@�@��������
�@�@�@�@�@�a�@�@�b�����x���Q
�@�@�@�@������������
�@�@�@�@�C�@���c�@�a�����x���R
�@�@�@�@�@�@�@�@������
�@�@�@�@�@�@�@�@�C�@��
�@��̗�ł́A�i���a�́A���x��2�ł��A���x��3�ł��o�����܂��B���̂Ƃ��A�i�ڂa�̃��[�E���x���E�R�[�h�́A3�ƂȂ�܂��B
�@�ʼn��ʂɂ����Ȃ�Ȃ��q�i�Ԃɂ́A���[���x���E�R�[�h��ݒ肷��K�v�͗L��܂���B
�@���i�\���A�o�b�`��������Ƃ��ɂ́A�e�q�W�̏����A���[���x���R�[�h�ŕ��ׂĎg���܂��B
�@�Ⴆ�AMRP(Material Requirements Planning)���v�ʌv�Z������Ƃ��ɂ́A���[���x���R�[�h�̏��������̂���傫�Ȃ��̂ɁA���Ɍv�Z���܂��B����́A���(�e)�̏��v�ʂ��S�ċ��܂������_�ŁA�e�̏��v�ʂ���A�����̕i�ڂ̏��v�ʂ��v�Z����̂ŁA���[���x���E�R�[�h���ɏ������Ă����A����ŁA�S�Ă̍\���i�̏��v�ʂ��A�v�Z�ł��邩��ł��B
�@�܂��A�d�ʗݐ�(���ݐς�A�����ςݏグ��)������ꍇ�́A���[���x���E�R�[�h�̋t���ɕ��ׂČv�Z���܂��B���ʂ̕i�ڂ̏d�ʂ̍��v���A��ʂ̕i�ڂ̗ݐϏd�ʂɂȂ�̂ŁA���̏��Ɍv�Z����A���̏����ŁA�S�Ă̕i�ڂ̗ݐϏd�ʂ��v�Z�ł��邱�ƂɂȂ�܂��B
���[���x���E�R�[�h�ݒ�(����1)
�@���L�́A�T���v�����i�\�f�[�^(�T���v��:bom0001_2.txt)����A���[���x���E�R�[�h��ݒ肵�āA���[���x���R�[�h���ɁA�\������}�N���ł��B
�@���̃e�L�X�g�E�t�@�C���́A���i�\���u�V���O���E���x���ŁA�e�q�̍\��������s���̃f�[�^�v�Ƃ��ĕ��ׂ����̂ł��B
�@���[���x���E�R�[�h��ݒ肷��ߒ��ŁA���i�\�f�[�^�� ���[�v�s� �������邱�Ƃ��ł��܂��B���[�v�Ƃ́A�����̎q��(�q��)�ɁA�������g���ēo�ꂷ��A�L���Ă͂����Ȃ��̂��Ƃł��B
�@�K���ȃt�H���_�ɁAbom0001_2.txt��ۑ����āALowLevelCodeVBA2.xls�����Ă݂ĉ������B
�����[���x���E�R�[�h�ݒ�̃A���S���Y����
�ǂݍ��A�f�[�^��1�s�ڂ���A�Ō�̍s�܂ŁA
�e�i�ڔԍ��ɂ��āA���̕i�ڔԍ����A�q�i�ڔԍ��ɑ��݂��邩�ǂ������`�F�b�N����B
�q�i�ڔԍ��ɑ��݂��Ȃ��ꍇ�́A���̐e�i�ڔԍ��̃��[���x���E�R�[�h�́A1(L)�ƂȂ�B
�܂��A1�s�ڂɖ߂��āA�Ō�̍s�܂ŁA���[���x���E�R�[�h���ݒ�̐e�i�ڔԍ��ɂ��āA
���̕i�ڔԍ����A���[���x���E�R�[�h���ݒ�A�������͐ݒ蒆�̃��[���x���̎q�i�ڔԍ���
���݂��邩�ǂ������`�F�b�N����B
�q�i�ڔԍ��ɑ��݂��Ȃ��ꍇ�́A���̐e�i�ڔԍ��̃��[���x���E�R�[�h�́AL+1�ƂȂ�B
������A���[���x���E�R�[�h���ݒ肳���Ώېe�i�ڔԍ����E�o����邩����A�J�Ԃ��B
(�ʏ�A�J�Ԃ���20���x�����x�ɐ������邱�Ƃ��ł���B)
�@���[���x���E�R�[�h���ݒ肳��Ȃ��\�����A���[�v�\���ɂȂ�܂��B
�@�z��A�Z���͈͂ɁA�f�[�^���ꊇ�o�^������A�t�ɁA�Z���͈͂��A��C�ɔz��ɓǂݍ��ނƁA�X�s�[�h�������A�֗��ł��B
�@Resize �v���p�e�B���g���āA�Z���͈͂��w�肵�āA�z����g�����@ �̍����A�Q�Ɖ������B
�@���́A�u���i�\�̃��[���x���E�R�[�h�ݒ�v�}�N���ł́A�\�[�g�����ŁA���̔z����g���Ă��܂��B
���[���x���E�R�[�h�ݒ�(����2)
�@��́A���[���x���E�R�[�h�ݒ�(����1)�ł́A�\���W�J�ɁAExcel�̕\���g���Ă��܂����B���ꂾ�ƁAExcel�̃��[�N�V�[�g�̃T�C�Y 65,536 �s ( Excel 2007�` �ł��A1,048,576 �s)�̐�����܂��B
�@�����ŏЉ��}�N���́A�e�i�ڔԍ��P�ʂɁA1�t�@�C�����쐬���āAMTFS�̋@�\���g�����Ƃɂ��A�������A�i�ړ_���̐����A�W��W�J�ł����悤�ɂ������̂ł��B
�@FAT 32 �ł́A��̃t�H���_�ɓo�^�ł���t�@�C�����́A65,534 �ɐ�������܂��B�������AMTFS ���ƁA�o�^�ł���t�@�C�����͖������ł��B
�@���̂��߁AMTFS �h���C�u�̃t�H���_�Ƀt�@�C����o�^����A�t�@�C�������g���ă_�C���N�g�Ƀt�@�C�����e��ǂݏo�������ł���̂ŁA�����_���E�A�N�Z�X�E�������Ƃ��Ďg�����̂ł��B
�@�{�̃������ł͂Ȃ��A�f�B�X�N�E�h���C�u����Ɨ̈�Ƃ��Ďg���̂ŁA��ʂ̍\���ɂ��Ή��ł��܂��B
�@���[�E���x���E�R�[�h�̐ݒ�ł́A�V���O�����x���t�W�J�𗘗p���Ă��܂��B
�@�e�i�ڔԍ����A�q�̗��ɂ��邩�ǂ����́A�V���O�����x���t�W�J���g���ƁA�V���O�����x���t�W�J�\���̗L���ŁA�u���ɔ��f�ł��܂��B
�@�@�@�@�@�@�@�`�����x���P
�@�@�@�@�@��������
�@�@�@�@�@�a�@�@�b�����x���Q
�@�@�@�@������������
�@�@�@�@�C�@���c�@�a�����x���R
�@�@�@�@�@�@�@�@������
�@�@�@�@�@�@�@�@�C�@��
| �V���O�����x�����W�J |
| �V���O�����x���t�W�J |
|
| LLC | �e(�L�[) | �q |
| �q(�L�[) | �e |
|
| 1 | A | B |
| B | A | ���A�폜 |
| A | C |
| B | C |
|
| 3 | B | �C |
| C | A | ���A�폜 |
| B | �� |
| D | C |
|
| 2 | C | B |
| �C | B |
|
| C | D |
| �� | B |
|
|
|
|
| ���@A�����݂��Ȃ��FA��LLC�́A1 |
|
|
|
|
|
| ���BC�����݂��Ȃ��FC��LLC�́A2 |
|
|
�@�\���̐e�i�ڔԍ����X�g(��̗�ł́AA,B,C)���A�V���O���E���x���t�W�J�̃L�[�Əƍ����āA�V���O���E���x���t�W�J�ɑ��݂��Ȃ��i�ڂ������܂��B(���̏ꍇ�́AA�̂�)
�@���̌��ʁALLC 1�́AA�����Ɗm�肵�܂��B�@
�@LLC 1�̃����o���S�������������_�ŁA�V���O���E���x���t�W�J����A�������e�i��(���̏ꍇ��A�̂�)�̍\�����A�폜���܂��B�A
�@�c�����e�i�ڔԍ����X�g(�����ł́AB,C)���A�c�����V���O���E���x���t�W�J�̃L�[�Əƍ����āA�V���O���E���x���t�W�J�ɑ��݂��Ȃ��i�ڂ������܂��B(���̏ꍇ�́AC�̂�)
�@���̌��ʁALLC 2�́AC�����Ɗm�肵�܂��B�B
�@�ȉ����l�ɁA�e�i�ڔԍ����ALLC�����肵�����̂���������ł����āA�S��LLC �����܂邩�A�������͊Y����������Ȃ��Ȃ�ALLC �T���͏I���ł��B
�@LLC�̍ő�l�́A�ΏۂƂ��镔�i�\���ŁA�Ⴂ�܂����A����قǑ傫�Ȑ��ł͂���܂���B
�@��̓�̃t�@�C�����A�u��p�t�H���_(�Ⴆ�� test )�v�ɕۑ����ĉ������B�����āA���̃t�H���_���� Excel ���J���āA�u�W��W�J�v�̃{�^���������܂��B
�@�ۑ������t�H���_�̒��ɃT�u�t�H���_�u���ʁv������āA�����ɁA�W��W�J���ʂ̃t�@�C��������܂��B
�ϐ��̐���
�@���O����
�@�V���O���\���t�@�C�����J�E���g���Ȃ���ǂݍ���ŁA�z��̃T�C�Y�����肷��B
�@(�z��́AVariant�^�����AString�^���g���������A������������Ȃ��B
�@�܂��AReDim Preserve �ŁA�����T�C�Y���g�傷������A�O�����ăT�C�Y���`���������A������������Ȃ��B)
�@��LLC �ݒ�
�@�V���O���\����ǂݍ��ނ��߂̔z��
�@�ꎞ�z��F�e�i��30�A�q�i��30�A�e�����萔��5�B�\�[�g���ʂ�����Ȃ��悤�ɌŒ蒷�ɂ��Ċi�[����B
�@�V���O���t�W�J�\����o�^���邽�߂̔z��(�z��s���́A��̃V���O���\����ǂݍ��ނ��߂̔z��Ɠ���)
�@�ꎞ�z��temp�F�q�i��30�A�e�i��30�A�e�����萔��5�A�eLLC3
�@�e�i�Ԃ�LLC��o�^���邽�߂̔z��
�@�e�i��LLC�z��F�e�i�ԁALLC
�@�u�e�i��LLC�z��v�ŁA�e�i�Ԃ��L�[�ɁA�z��̊Y���s�����������邽�߂̘A�z�z��
�@�e�i�ԍ����F�e�i�ԁA�e�i��LLC�z��ł̊Y���s�������A�z�z��
�@���W��W�J
�@�V���O���\����ǂݍ��ނ��߂̔z��
�@�ꎞ�z��F�e�i��30�A�q�i��30�A�e�����萔��5�B�\�[�g���ʂ�����Ȃ��悤�ɌŒ蒷�ɂ��Ċi�[����B
�@�e�i��LLC�z��F�e�i�ԁALLC�����LLC�ݒ�ō�����z�̂���
�@�W��W�J�\���͋���(�S�̂̍\���s���́A�V���O���\����8�{���x�ɂȂ�)�ɂȂ�
�@���̃}�N���ŁA�^���[�J����̍\���f�[�^���A�V���O����LLC�ݒ聨�W��W�J�������ʂ́A���L�̂悤�ɂȂ�܂����B
�@���������̃p�\�R�����g���A6�S�����̕��i�\�\���ł��A���p���x���̏������ԂŏW��W�J�ł��邱�Ƃ�������܂����B(�W��W�J�̏o�͍s���́A7�疜�s�I)

| �� | �敪 | �e�i�ԓ_�� | �q�i�ԓ_�� | �i�ԓ_�� | �\��(�V���O���e�q�W)�� | �W��W�J
�������� | �W��W�J
�\������ |
| 1 | bom0001_3.txt | 268 | 1,008 | 1,036 | 1,841 | (0.2��) | 12,129 |
| 2 | �q��f�[�^1 | 274,794 | 525,325 | 596,291 | 2,523,033 | 3.5H | 33,223,076 |
| 3 | �q��f�[�^2 | 802,095 | 1,459,990 | 1,643,284 | 6,038,432 | 12H | 70,676,411 |
�@���i�\�́A�e�i�ڂƁA�q�i�ڂ́u�W�f�[�^�v�̂��߁A�W�J�ɃV�[�P���V�����������g���ƁA�\���_����������ƁA�����Ɋ|���Z�Ŏ��Ԃ�������܂��B(�Ⴆ�A�\��������10�{���ƁA�e10�~�q10�ŁA100�{)
�@����ɑ��āA���̃}�N���́A�����_���E�A�N�Z�X���g���Ă���̂ŁA�\���_���ƁA�������Ԃ��A���j�A�Ƃ͂����܂��A�����I�ȑ����ɂ͂Ȃ��Ă��Ȃ��Ƃ��낪�~�\�ł��B
�@�V���O���\�������́A�������̔z��ɓo�^����̂ŁA�����ł���\�����́A�������Ɉˑ����܂��B
�@�A�z�z����g�����A�i�ڔԍ����L�[�Ƃ��Ĕz��̊Y���������Q�Ƃ��Ă��܂��B
�@����F
�@�������Ă���Excel�̃p�X�́A���L�ŋ��߂Ă��܂��B
�@�@���݂̃p�X = ActiveWorkbook.Path
�������́A
�@�@���݂̃p�X = ThisWorkbook.Path
�V���O���t�W�J���o��
�@�ȉ��́A�V���O�����W�J�t�@�C����ǂ�ŁA�V���O���t�W�J�t�@�C�����쐬���镔���ł��B
�@ForAppending ���g���āA�NjL�����o�����Ă��܂��B
���i�\�W��W�J
�@LLC�̑傫�����̂���(���i�\�̍ʼn��ʍ\������)�A���Ɏq�i�ڂ̕i�ڔԍ��ƁA���̍\�����ʂ�ݐς��Ă����܂��B
�@LLC���g���ďW�邽�߁A��̐e�i�ڂ́A�����E�W�J�͈���ŁA�����ɏ����ł��܂��B
�@�e�i�ڂ̒����̍\���́A�V���O�����x���̍\�������̂܂g���܂��B���́A���Ɍv�Z�ς��̏W��W�J�̌��ʂ��g���܂��B
�@�ʏ�A�W��W�J�̉ߒ��ŁA����i�ڔԍ����\���q�i�ڂƁA���i�ڂƂ̗������畡���s�ɓW�J����Ă��܂��B�\�[�g����Ɠ���q�i�ڔԍ������Ԃ̂ŁA����q�i�ڔԍ��̐��ʂ����v���āA��i�ڔԍ��ɂ��Ĉ�s�����A�W��W�J���ʂɏo�����܂��B
�@���̂��߁A�e�i�ڒP�ʂ̏W��\���̌������ʂ��A�������� Excel �̃V�[�g�u���[�N�v�ɏ����o���܂��B
�@���̃��[�N�ɏ����o�������̂��AExcel�̋@�\���g���ă\�[�g���܂��B
(��i�ڂ̍\���q�i�ڂ́A�������� 65,536 �s�܂łɂ͂Ȃ�Ȃ��̂ŁAExcel�V�[�g�̕��ёւ��@�\���g���Ă��܂��B)
�@�}�N���ƃT���v���E�f�[�^�́A���[���x���E�R�[�h�ݒ�(����2)�̂Ƃ���Ɍf�ڂ��Ă��܂��B
�@�A�z�z����g�����A�i�ڔԍ����L�[�ɁA�z��̊Y���������Q�Ƃ��Ă��܂��B
| ���x��= 17 | �W��W�J�\������= 2 | ���Y���x����������= 0����00��00�b | �ݐ�= 0����21��53�b |
| ���x��= 16 | �W��W�J�\������= 12 | ���Y���x����������= 0����00��00�b | �ݐ�= 0����21��53�b |
| ���x��= 15 | �W��W�J�\������= 45 | ���Y���x����������= 0����00��00�b | �ݐ�= 0����21��53�b |
| ���x��= 14 | �W��W�J�\������= 199 | ���Y���x����������= 0����00��01�b | �ݐ�= 0����21��54�b |
| ���x��= 13 | �W��W�J�\������= 629 | ���Y���x����������= 0����00��00�b | �ݐ�= 0����21��54�b |
| ���x��= 12 | �W��W�J�\������= 2,041 | ���Y���x����������= 0����00��02�b | �ݐ�= 0����21��56�b |
| ���x��= 11 | �W��W�J�\������= 6,309 | ���Y���x����������= 0����00��05�b | �ݐ�= 0����22��01�b |
| ���x��= 10 | �W��W�J�\������= 17,833 | ���Y���x����������= 0����00��13�b | �ݐ�= 0����22��14�b |
| ���x��= 9 | �W��W�J�\������= 50,572 | ���Y���x����������= 0����00��38�b | �ݐ�= 0����22��52�b |
| ���x��= 8 | �W��W�J�\������= 142,366 | ���Y���x����������= 0����01��45�b | �ݐ�= 0����24��37�b |
| ���x��= 7 | �W��W�J�\������= 376,111 | ���Y���x����������= 0����05��16�b | �ݐ�= 0����29��53�b |
| ���x��= 6 | �W��W�J�\������= 947,833 | ���Y���x����������= 0����09��15�b | �ݐ�= 0����39��08�b |
| ���x��= 5 | �W��W�J�\������= 2,220,503 | ���Y���x����������= 0����17��16�b | �ݐ�= 0����56��24�b |
| ���x��= 4 | �W��W�J�\������= 5,359,284 | ���Y���x����������= 0����29��59�b | �ݐ�= 1����26��23�b |
| ���x��= 3 | �W��W�J�\������= 12,928,118 | ���Y���x����������= 1����28��13�b | �ݐ�= 2����54��36�b |
| ���x��= 2 | �W��W�J�\������= 32,437,979 | ���Y���x����������= 2����12��41�b | �ݐ�= 5����07��17�b |
| ���x��= 1 | �W��W�J�\������= 70,676,411 | ���Y���x����������= 2����50��03�b | �ݐ�= 7����57��20�b |
 �@�i�ԕʂ̏W��W�J���A�i�ԕʂ̃e�L�X�g�E�t�@�C���ɏ����o�������A�z��Ɋi�[�����ق������R�����ɂȂ�܂��B
�@�i�ԕʂ̏W��W�J���A�i�ԕʂ̃e�L�X�g�E�t�@�C���ɏ����o�������A�z��Ɋi�[�����ق������R�����ɂȂ�܂��B
�@�������A�z��̍\�����������Ȃ�ƁA�����������ŁA�u������̈悪�s�����Ă��܂��B�v�ƂȂ��ďW��W�J�ł��܂���B
�@���̂��߁A�����ł͑�ʂ̍\���ł��W�J�ł���悤�ɁA�i�ڔԍ��ʂ̏W��W�J���ʂ́AMTFS ���g���āA�e�i�ڔԍ��P�ʂ̃e�L�X�g�E�t�@�C���ɏ����o���Ă��܂��B
�@�i�ڔԍ����t�@�C�����Ƃ��Ďg���Ȃ������́A���[�U���Œu�����Ă��܂��B
�@�t�@�C�����Ƃ��Ďg���Ȃ��֎~�������A���i�ԍ��̕�����Ƃ��ďo�����Ȃ��āA�t�@�C�����Ƃ��Ďg�����S�p�����ɕϊ�����A���[�U���B
���i�\�}���`�E���x���W�J�E�}���`�E���x���t�W�J
�@�g�����F
�@�W��BOM�t�@�C��(�T���v��:bom0001_2.txt)���A�K���ȃt�H���_�ɕۑ����܂��B
�@�����āA�}�N���̃{�^���������܂��B�}�N������A�t�@�C���̏ꏊ���Ă��܂��B
�@(�����VBA�̍�)
���i�\�}���`�E���x�����V���O���E���x�����o
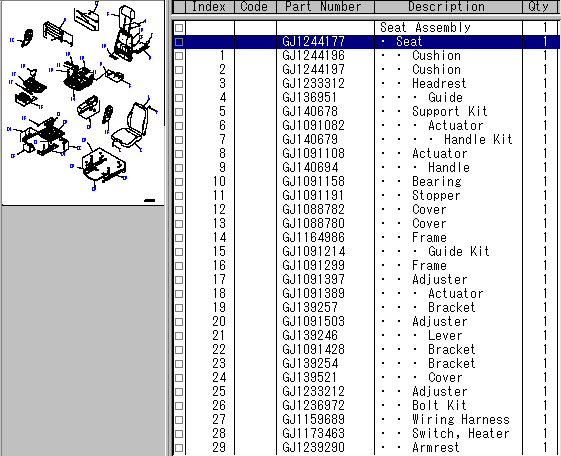 �@�E�̐}�́A���i�\�̃}���`�E���x���W�J�\���̗�ł��B
�@�E�̐}�́A���i�\�̃}���`�E���x���W�J�\���̗�ł��B
�@�E�̐}�ŁA�E�̐������x����\���Ă��܂��B
�@�}���`�E���x���̃f�[�^�́A���̃��x���̓r���ɁA���ʂ̃��x�������܂��Ă��܂��B
���̂��߁A���ꃌ�x�����܂Ƃ߂邽�߂ɁA���x�����ɒ��o�����f�[�^���A�\�[�g���āA�e�i�ڔԍ��P�ʂɂ܂Ƃ߂Ă��܂��B
�@�܂��A�}���`�E���x���̃f�[�^�́A����\�����A�d�����ďo������\��������܂��B���̂��߁A�}�N���ł́A�\�[�g��ɁA�d���f�[�^���s�폜���Ă��܂��B
�@���̃}�N���ł́ACSV ����ǂݍ��}���`�E���x���̃f�[�^���A��s���ƂɁA�ꌳ�z��́u�f�[�^�z��(28)�v�Ɋi�[���Ă��܂��B
�z��f�[�^���A�Z���Q�ɒ��ڏ����o�����߂ɂ́A�z��͓z��łȂ���Ȃ�܂���B���̂��߁A�ꌳ�z��ɓǂ݂��f�[�^�́ATranspose ���g���āA�z��Ɋi�[�������Ă��܂��B
�@�q�i�ڔԍ��ɑΉ�����e�i�ڔԍ��́A�u�e�i�Ԕz��(10, 28)�v �Ƀ��x�����Ɋi�[���܂��B
�����ł́A���x����10�܂łƂ��āA�z��̍s���㏑�����邱�ƂŁA���x�����ɓǂݍ��Ō�̍s�f�[�^�݂̂��e�i�Ԕz��Ɏc��悤�ɂ��Ă��܂��B
�@CSV �t�@�C���̓ǂݍ��ݕ����́AExcel�ł��d���I �� CSV�`���e�L�X�g�f�[�^�̓ǂݍ��� �̃R�[�h���g�킹�Ă��������Ă��܂��B
�@���̃}�N���ƃT���v���E�f�[�^���_�E�����[�h�ł��܂��B
�@���
Input # �X�e�[�g�����g �́A�V�[�P���V�������̓��[�h (Input) �ŊJ�����t�@�C������f�[�^��ǂݍ���ŁA�����ϐ��Ɋi�[����t�@�C�����o�̓X�e�[�g�����g�ł��B
�@�\��
�@Input #filenumber, varlist
�@Input # �X�e�[�g�����g�̍\���́A���̎w�荀�ڂ���\������܂��B
| �w�荀�� |
���e |
| filenumber |
�K���w�肵�܂��B�C�ӂ̃t�@�C���ԍ����w�肵�܂��B |
| varlist |
�K���w�肵�܂��B�t�@�C������ǂݍ��f�[�^���i�[���邽�߂̕ϐ����A1 �܂��͕����w�肵�܂��B
�����w�肷��Ƃ��́A�J���} (,) �ŋ���Ďw�肵�܂��B
�z��ϐ��A���[�U�[��`�^�̕ϐ��A�܂��̓I�u�W�F�N�g�ϐ����w�肷�邱�Ƃ͂ł��܂���B
�������A�z��̗v�f�܂��̓��[�U�[��`�^�̗v�f�́A�w��ł��܂��B |
�@�ʏ�AInput # �X�e�[�g�����g���g�p���ēǂݍ��f�[�^�́AWrite # �X�e�[�g�����g���g�p���ď������݂܂��B
Input # �X�e�[�g�����g�́A�V�[�P���V�������̓��[�h (Input) �܂����o�C�i�� ���[�h (Binary) �ŊJ�����t�@�C���ɑ��Ă����g�p���܂��B
�@�t�@�C������f�[�^��ǂݍ��ޏꍇ�A�ʏ�A������f�[�^�͕�����^ (String)�A���l�f�[�^�͐��l�f�[�^�^�Ƃ��Ċi�[����܂��B
����ȊO�̃f�[�^��ǂݍ��ꍇ�A���Ɏ����悤�Ƀf�[�^�ɂ���ĕϐ��Ɋ��蓖�Ă���^���قȂ�܂��B
| �f�[�^ |
�ϐ��Ɋi�[�����l |
| �J���}�̂݁A�܂��͋s |
Empty �l (VarType 0) |
| #NULL# |
Null �l (VarType 1) |
| #TRUE# �܂��� #FALSE# |
�^ (True) �܂����U (False) |
| #yyyy-mm-dd hh:mm:ss# |
���ɂ���ĕ\���ꂽ���t�Ǝ��� |
| #ERROR errornumber# |
errornumber (�G���[�l�Ƃ��Ċi�[���ꂽ�o���A���g�^ (Variant) |
�@���̓f�[�^���̃_�u�� �N�H�[�e�[�V���� ("") �͖�������܂��B
�@����
�@Input # �X�e�[�g�����g�ŁA"1,2""X" �̂悤�ȃN�H�[�e�[�V�������܂ޕ�������L�q���Ȃ��悤�ɂ��Ă��������B
���̂悤�ȏꍇ�A�Ɨ����� 2 �̕�����Ƃ��ĔF������܂��B
�@�t�@�C�����̃f�[�^���ڂ̏��Ԃ́A���� varlist �Ŏw�肵���ϐ��̏��Ԃƈ�v���Ă���K�v������܂��B
�܂��A�t�@�C�����̊e�f�[�^���ڂ̃f�[�^�^�́A�Ή�����ϐ��̃f�[�^�^�ƈ�v���Ă��Ȃ���Ȃ�܂���B
���Ƃ��A�ϐ������l�f�[�^�^�œǂݍ��ރf�[�^�����l�f�[�^�^�łȂ��ꍇ�A�ϐ��ɂ� 0 ���������܂��B
�@�f�[�^����͂��Ă���Ƃ��Ƀt�@�C���̖����ɒB����ƁA���͂��I�����A�G���[���������܂��B
�@����
�@Input # �X�e�[�g�����g���g�p���ăt�@�C������ϐ��փf�[�^�𐳂����ǂݍ��ނ��Ƃ��ł���悤�ɁA�f�[�^���t�@�C���ɏ������ޏꍇ�́APrint # �X�e�[�g�����g�ł͂Ȃ��A�K�� Write # �X�e�[�g�����g���g�p���Ă��������B
Write # �X�e�[�g�����g���g�p����ƁA�t�@�C���Ƀf�[�^���������ނƂ��Ɋe�f�[�^���ڂ̊Ԃɐ������J���} (,) ���}������܂��B
�@�g�p��
�@���̗�́AInput # �X�e�[�g�����g���g���āA�t�@�C���̃f�[�^��ǂݍ��݁A2 �̕ϐ��ɑ�����Ă��܂��B
���̗�̃t�@�C�� TESTFILE �ɂ́AWrite # �X�e�[�g�����g���g���āA�f�[�^���������܂�Ă�����̂Ɖ��肵�܂��B
�f�[�^�́A"Hello", 234 �̂悤�ɁA������̓_�u�� �N�H�[�e�[�V���� (") �ň͂܂�A���l�̓J���} (,) �ŋ���Ă��܂��B
�@FreeFile �� �́A�g�p�\�ȃt�@�C���ԍ��𐮐��^ (Integer) �̒l�ŕԂ��t�@�C�����o�͊��ł��B
�@�\��
�@FreeFile[(rangenumber)]
�@���� rangenumber �ɂ́A�t�@�C���ԍ��͈̔͂��o���A���g�^ (Variant) �Ŏw�肵�܂��B�w�肵���͈͂��玟�Ɏg�p�\�ȃt�@�C���ԍ���Ԃ��܂��B���̈����͏ȗ��\�ł��B
�@0 (����l)1 �` 255 �͈̔͂̃t�@�C���ԍ����Ԃ���܂��B
�@1256 �` 511 �͈̔͂̃t�@�C���ԍ����Ԃ���܂��B
�@�g�p�\�ȃt�@�C���ԍ����擾���邽�߂� FreeFile �����g�p���܂��B
���Ɏg���Ă���t�@�C���ԍ����d�����Ďg���̂�h�����Ƃ��ł��܂��B
�@�g�p��
�@���̗�́AFreeFile �����g���āA���Ɏg�p�\�ȃt�@�C���ԍ���Ԃ��܂��B
���̗�ł́A���[�v���� 5 �̃t�@�C�����V�[�P���V�����o�̓��[�h (Output) �ŊJ���Ă��܂��B
�e�t�@�C���ɂ́A�T���v�� �f�[�^���������܂�Ă�����̂Ɖ��肵�܂��B